import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import warnings
import bambi as bmb
warnings.simplefilter(action="ignore", category=FutureWarning)Plot Predictions
This notebook shows how to use, and the capabilities, of the plot_predictions function. The plot_predictions function is a part of Bambi’s sub-package interpret that features a set of tools used to interpret complex regression models that is inspired by the R package marginaleffects.
Interpreting Generalized Linear Models
The purpose of the generalized linear model (GLM) is to unify the approaches needed to analyze data for which either: (1) the assumption of a linear relation between \(x\) and \(y\), or (2) the assumption of normal variation is not appropriate. GLMs are typically specified in three stages:
- the linear predictor \(\eta = X\beta\) where \(X\) is an \(n\) x \(p\) matrix of explanatory variables.
- the link function \(g(\cdot)\) that relates the linear predictor to the mean of the outcome variable \(\mu = g^{-1}(\eta) = g^{-1}(X\beta)\)
- the random component specifying the distribution of the outcome variable \(y\) with mean \(\mathbb{E}(y|X) = \mu\).
Based on these three specifications, the mean of the distribution of \(y\), given \(X\), is determined by \(X\beta: \mathbb{E}(y|X) = g^{-1}(X\beta)\).
GLMs are a broad family of models where the output \(y\) is typically assumed to follow an exponential family distribution, e.g., Binomial, Poisson, Gamma, Exponential, and Normal. The job of the link function is to map the linear space of the model \(X\beta\) onto the non-linear space of a parameter like \(\mu\). Commonly used link function are the logit and log link. Also known as the canonical link functions. This brief introduction to GLMs is not meant to be exhuastive, and another good starting point is the Bambi Basic Building Blocks example.
Due to the link function, there are typically three quantities of interest to interpret in a GLM:
- the linear predictor \(\eta\)
- the mean \(\mu = g^{-1}(\eta)\)
- the response variable \(Y \sim \mathcal{D}(\mu, \theta)\) where \(\mu\) is the mean parameter and \(\theta\) is (possibly) a vector that contains all the other “nuisance” parameters of the distribution.
As modelers, we are usually more interested in interpreting (2) and (3). However, \(\mu\) is not always on the same scale of the response variable and can be more difficult to interpret. Rather, the response scale is a more interpretable scale. Additionally, it is often the case that modelers would like to analyze how a model parameter varies across a range of explanatory variable values. To achieve such an analysis, Bambi has taken inspiration from the R package marginaleffects, and implemented a plot_predictions function that plots the conditional adjusted predictions to aid in the interpretation of GLMs. Below, it is briefly discussed what are conditionally adjusted predictions, how they are computed, and ultimately how to use the plot_predictions function.
Conditionally Adjusted Predictions
Adjusted predictions refers to the outcome predicted by a fitted model on a specified scale for a given combination of values of the predictor variables, such as their observed values, their means, or some user specified grid of values. The specification of the scale to make the predictions, the link or response scale, refers to the scale used to estimate the model. In normal linear regression, the link scale and the response scale are identical, and therefore, the adjusted prediction is expressed as the mean value of the response variable at the given values of the predictor variables. On the other hand, a logistic regression’s link and response scale are not identical. An adjusted prediction on the link scale will be represented as the log-odds of a successful response given values of the predictor variables. Whereas an adjusted prediction on the response scale gives the probability that the response variable equals 1. The conditional part of conditionally adjusted predictions represents the specific predictor(s) and its values we would like to condition on when plotting predictions.
Computing Adjusted Predictions
The objective of plotting conditional adjusted predictions is to visualize how a parameter of the (conditional) response distribution varies as a function of (some) explanatory variables. In predictions, there are three scenarios to compute conditional adjusted predictions:
- user provided values
- a grid of equally spaced and central values
- empirical distribution (original data used to fit the model)
In the case of (1) above, a dictionary is passed with the explanatory variables as keys, and the values to condition on are the values. With this dictionary, Bambi assembles all pairwise combinations (transitions) of the specified explanatory variables into a new “hypothetical” dataset. Covariates not existient in the dictionary are held at their mean or mode.
In (2), a string or list is passed with the name(s) of the explanatory variable(s) to create a grid of equally spaced values. This is done by holding all other explanatory variables constant at some specified value, a reference grid, that may or may not correspond to actual observations in the dataset used to fit the model. By default, the plot_predictions function uses a grid of 200 equally spaced values between the minimum and maximum values of the specified explanatory variable as the reference grid.
Lastly, in (3), the original data used to fit the model is used to compute predictions. This is known as unit level predictions.
Using the data, from scenario 1, 2, or 3, the plot_predictions function uses the fitted model to then compute the predictions. The plot_predictions function then uses these predictions to plot the model parameter as a function of (some) explanatory variable.
Gaussian Linear Model
For the first demonstration, we will use a Gaussian linear regression model with the mtcars dataset to better understand the plot_predictions function and its arguments. The mtcars dataset was extracted from the 1974 Motor Trend US magazine, and comprises fuel consumption and 10 aspects of automobile design and performance for 32 automobiles (1973–74 models). The following is a brief description of the variables in the dataset:
- mpg: Miles/(US) gallon
- cyl: Number of cylinders
- disp: Displacement (cu.in.)
- hp: Gross horsepower
- drat: Rear axle ratio
- wt: Weight (1000 lbs)
- qsec: 1/4 mile time
- vs: Engine (0 = V-shaped, 1 = straight)
- am: Transmission (0 = automatic, 1 = manual)
- gear: Number of forward gear
# Load data
data = bmb.load_data('mtcars')
data["hp"] = data["hp"].astype(pd.Float32Dtype())
data["cyl"] = data["cyl"].replace({4: "low", 6: "medium", 8: "high"})
data["gear"] = data["gear"].replace({3: "A", 4: "B", 5: "C"})
data["cyl"] = pd.Categorical(data["cyl"], categories=["low", "medium", "high"], ordered=True)
# Define and fit the Bambi model
model = bmb.Model("mpg ~ 0 + hp * wt + cyl + gear", data)
idata = model.fit(draws=1000, target_accept=0.95, random_seed=1234)Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [sigma, hp, wt, hp:wt, cyl, gear]Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 8 seconds.We can print the Bambi model object to obtain the model components. Below, we see that the Gaussian linear model uses an identity link function that results in no transformation of the linear predictor to the mean of the outcome variable, and the distrbution of the likelihood is Gaussian.
Default values
Now that we have fitted the model, we can visualize how a model parameter varies as a function of (some) interpolated covariate. For this example, we will visualize how the mean response mpg varies as a function of the covariate hp.
The Bambi model, ArviZ inference data object (containing the posterior samples and the data used to fit the model), and a list or dictionary of covariates, in this example only hp, are passed to the plot_predictions function. The plot_predictions function then computes the conditional adjusted predictions for each covariate in the list or dictionary using the method described above. The plot_predictions function returns a Seaborn objects Plot object that can be further customized.
bmb.interpret.plot_predictions(model, idata, "hp")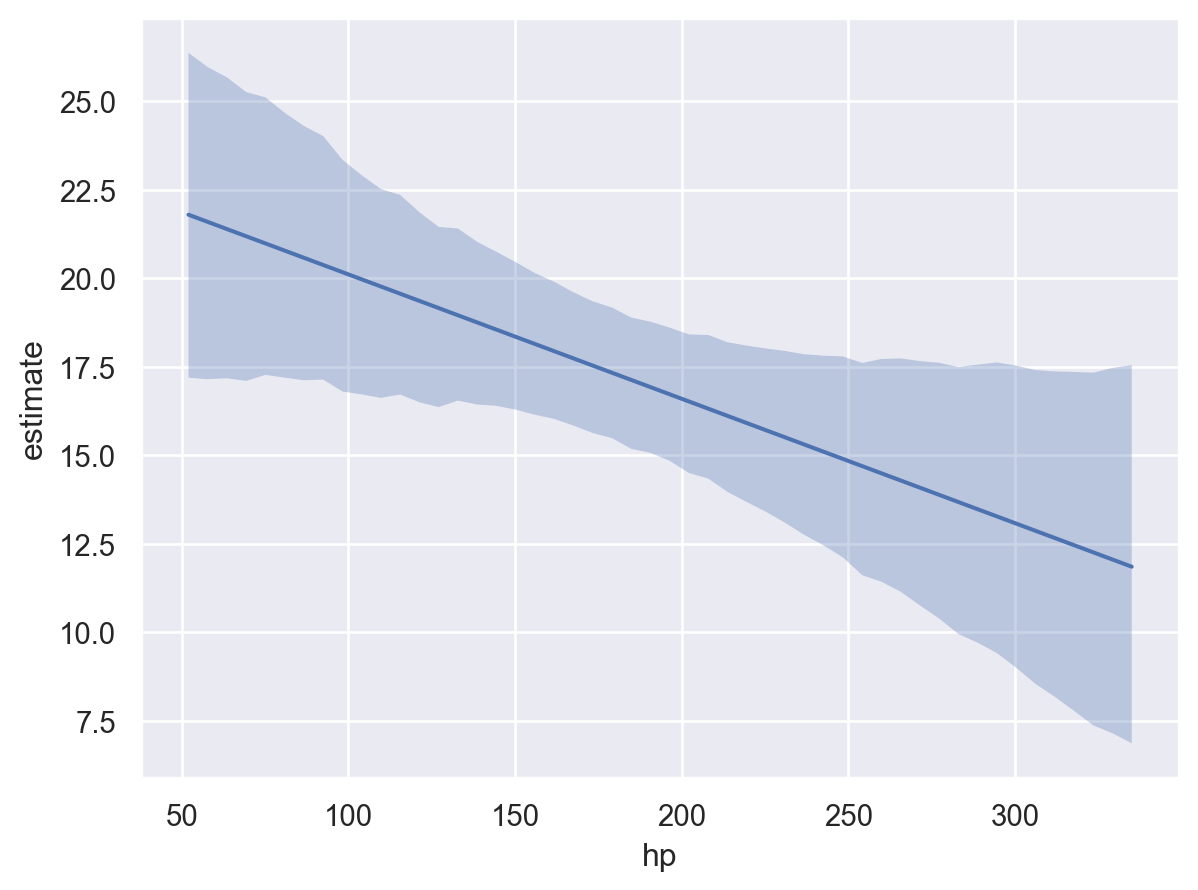
The plot above shows that as hp increases, the mean mpg decreases. As stated above, this insight was obtained by creating the reference grid and then using the fitted model to compute the predicted values of the model parameter, in this example mpg, at each value of the reference grid.
By default, plot_predictions uses the highest density interval (HDI) of the posterior distribution to compute the credible interval of the conditional adjusted predictions. The HDI is a Bayesian analog to the frequentist confidence interval. The HDI is the shortest interval that contains a specified probability of the posterior distribution. By default, plot_predictions uses the 94% HDI.
plot_predictions uses the posterior distribution by default to visualize the mean outcome parameter (i.e., target="mean"). However, the posterior predictive distribution can also be plotted by specifying target="mpg", which draws samples from the full response distribution rather than just the mean parameter.
bmb.interpret.plot_predictions(model, idata, "hp", target="mpg")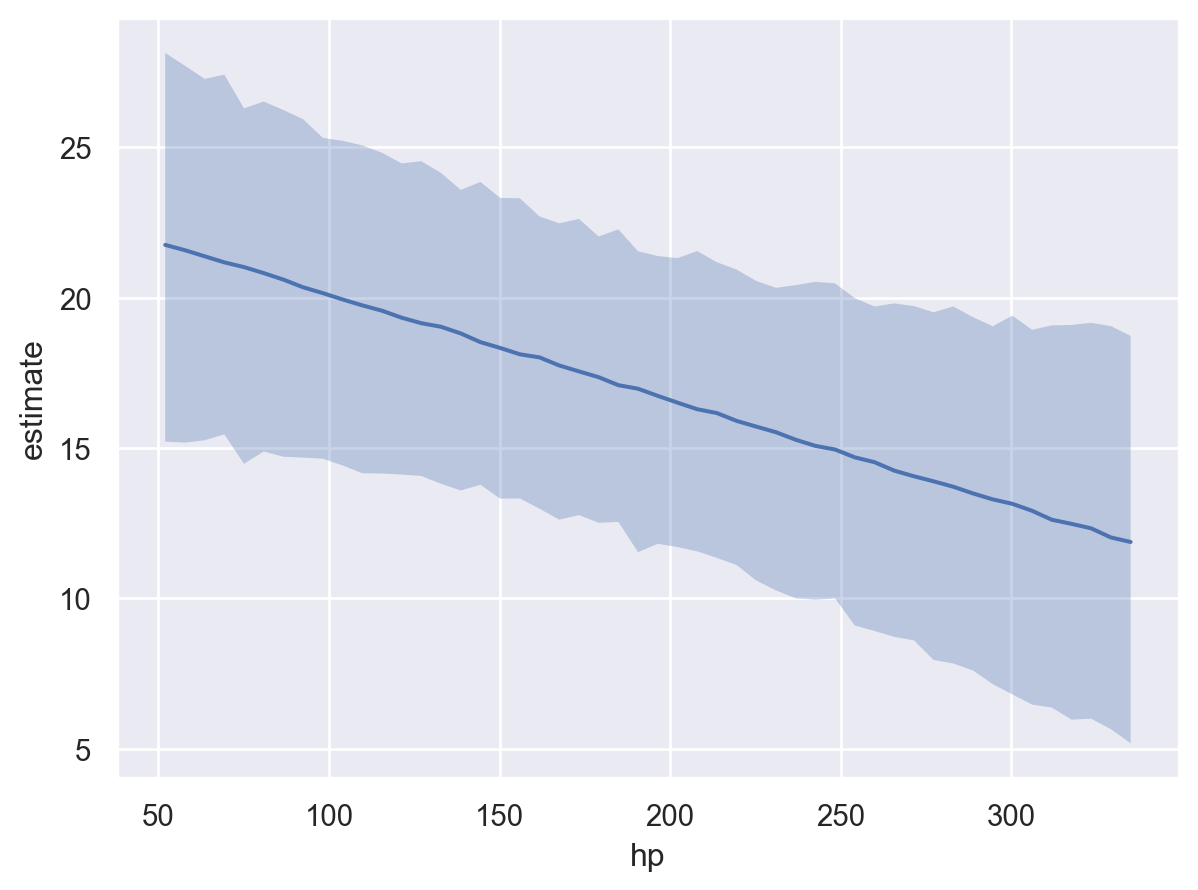
Here, we notice that the uncertainty in the conditional adjusted predictions is much larger than the uncertainty when using the default target="mean". This is because the posterior predictive distribution accounts for the uncertainty in the model parameters and the uncertainty in the data. Whereas, the posterior distribution only accounts for the uncertainty in the model parameters.
Additionally, predictions can be called to obtain the computed result directly. predictions returns a Result named tuple with two fields: summary and draws. The summary field is a pandas DataFrame containing the point estimates (posterior mean) and credible intervals for each row of the prediction grid. The draws field is an arviz.InferenceData object containing the full posterior samples used to compute the summary. The summary is useful for quick inspection and tabular reporting, while draws gives access to the complete posterior distribution for custom analyses or visualizations beyond the default summary statistics. The covariate columns in the summary dataframe are used to create the plot.
result = bmb.interpret.predictions(model, idata, "hp", target="mpg")
result.summary.head(10)| hp | cyl | gear | wt | estimate | lower_3.0% | upper_97.0% | |
|---|---|---|---|---|---|---|---|
| 0 | 52.0 | high | A | 3.21725 | 21.681850 | 15.166327 | 27.932473 |
| 1 | 57.775509 | high | A | 3.21725 | 21.612198 | 15.171167 | 27.710238 |
| 2 | 63.551022 | high | A | 3.21725 | 21.368589 | 15.167547 | 27.418414 |
| 3 | 69.32653 | high | A | 3.21725 | 21.118299 | 15.240909 | 27.289663 |
| 4 | 75.102043 | high | A | 3.21725 | 20.888421 | 14.790522 | 26.376599 |
| 5 | 80.877548 | high | A | 3.21725 | 20.706621 | 14.619215 | 26.124102 |
| 6 | 86.653061 | high | A | 3.21725 | 20.535748 | 14.170284 | 25.975069 |
| 7 | 92.428574 | high | A | 3.21725 | 20.325674 | 14.758248 | 25.752243 |
| 8 | 98.204086 | high | A | 3.21725 | 20.165396 | 14.737571 | 25.633363 |
| 9 | 103.979591 | high | A | 3.21725 | 19.967282 | 14.396180 | 25.330355 |
plot_predictions allows up to three covariates to be plotted simultaneously where the first element in the list represents the main (x-axis) covariate, the second element the group (hue / color), and the third element the facet (panel). However, when plotting more than one covariate, it can be useful to pass specific group and panel arguments to aid in the interpretation of the plot. Therefore, subplot_kwargs allows the user to manipulate the plotting by passing a dictionary where the keys are {"main": ..., "group": ..., "panel": ...} and the values are the names of the covariates to be plotted. For example, passing two covariates hp and wt and specifying subplot_kwargs={"main": "hp", "group": "wt", "panel": "wt"}.
bmb.interpret.plot_predictions(
model=model,
idata=idata,
conditional={"hp": np.linspace(50, 350, 50), "wt": np.linspace(1, 6, 5)},
subplot_kwargs={"main": "hp", "group": "wt", "panel": "wt"},
fig_kwargs={"theme": {"figure.figsize": (12, 5)}, "title": "wt={}".format}
).layout(extent=[0, 0, 0.92, 1]).show()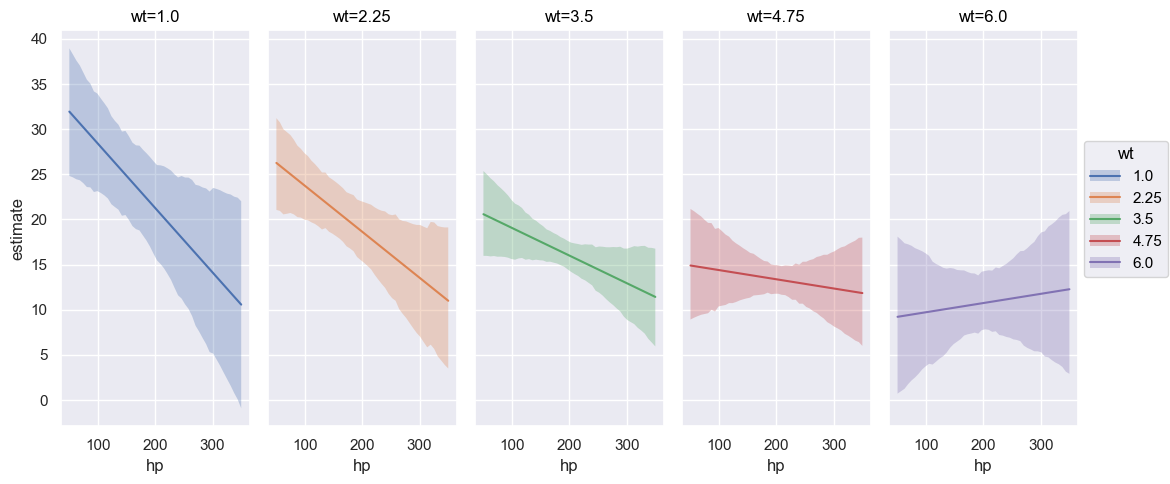
Furthermore, categorical covariates can also be plotted. We plot the the mean mpg as a function of the two categorical covariates gear and cyl below. The plot_predictions function automatically plots the conditional adjusted predictions for each level of the categorical covariate. Furthermore, when passing a list of covariates into the plot_predictions function, the list will be converted into a dictionary object where the key is taken from (“horizontal”, “color”, “panel”) and the values are the names of the variables. By default, the first element of the list is specified as the “horizontal” covariate, the second element of the list is specified as the “color” covariate, and the third element of the list is mapped to different plot panels.
bmb.interpret.plot_predictions(model, idata, ["gear", "cyl"])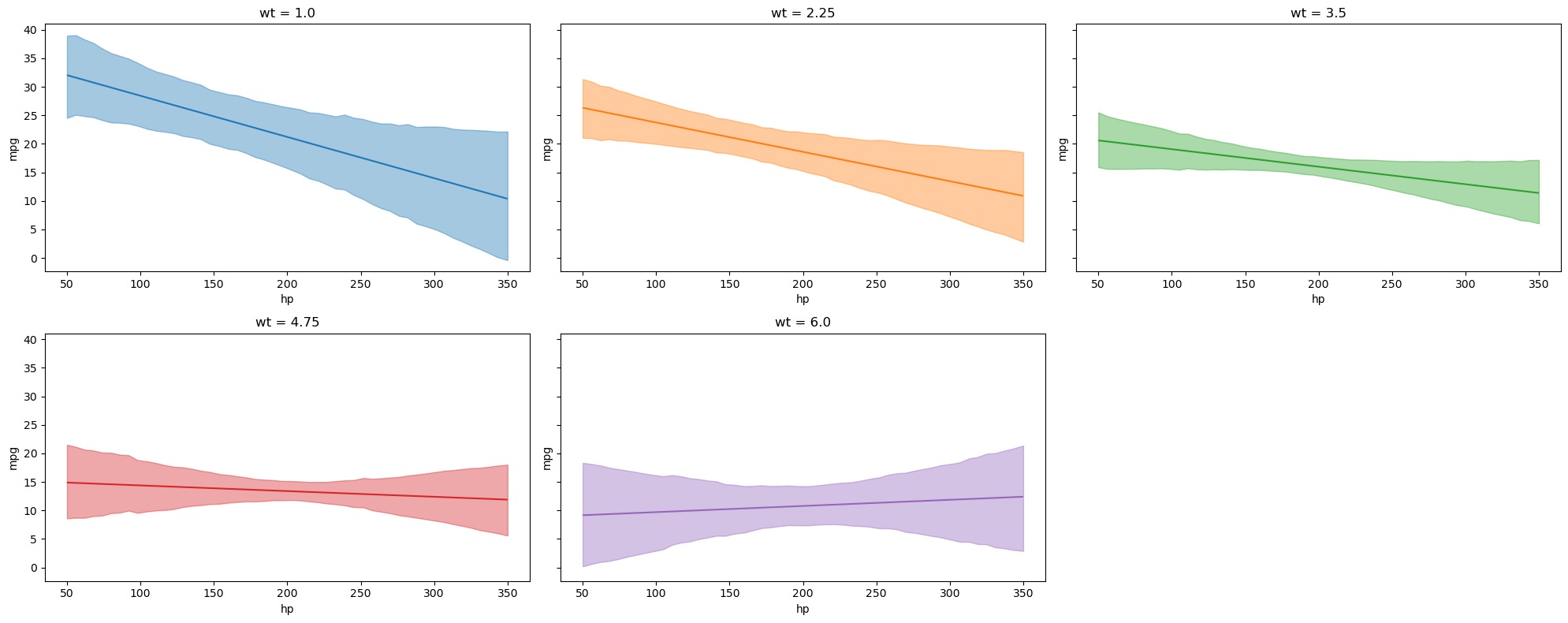
User provided values
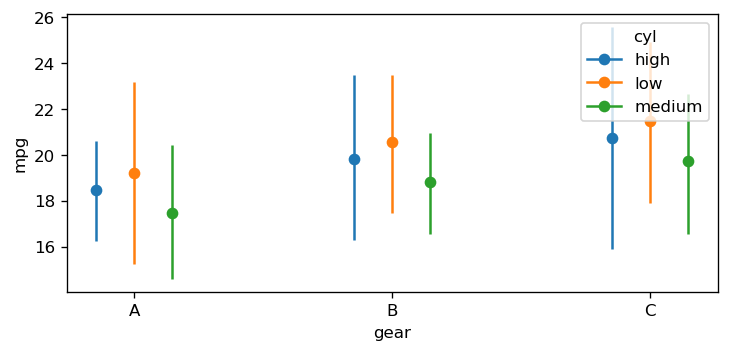
In the previous example, default values were computed to construct a reference grid to compute the conditional adjusted predictions. We can also pass our own values for the covariates into conditional using a dictionary where the key-value pairs are the covariate and value(s) of interest. For example, if we wanted to compute the predictions for hp=100, wt=[1.5, 3.5], and cyl=["low", "medium", "high"] we would pass the following dictionary in the code block below. As can be seen, several data types can be passed such as: np.ndarray, list, int, float, and str.
Furthermore, Bambi by default, maps the order of the dict keys to the main, group, and panel of the Seaborn plot object. Below, since hp is the first key, this is used for the x-axis, wt for the group (color), and cyl for the panel (facet).
bmb.interpret.plot_predictions(
model,
idata,
conditional={
"hp": [100, 120],
"wt": np.array([1.5, 3.5]),
"cyl": ["low", "medium", "high"]
},
)
Before the plot is described, lets see how the dictionary passed to conditional was used to create the dataset in order to compute predictions.
result = bmb.interpret.predictions(
model,
idata,
conditional={
"hp": [100, 120],
"wt": np.array([1.5, 3.5]),
"cyl": ["low", "medium", "high"]
},
)
result.summary| hp | wt | cyl | gear | estimate | lower_3.0% | upper_97.0% | |
|---|---|---|---|---|---|---|---|
| 0 | 100.0 | 1.5 | low | A | 27.302567 | 23.779355 | 31.279921 |
| 1 | 100.0 | 1.5 | medium | A | 25.520421 | 20.970180 | 29.633584 |
| 2 | 100.0 | 1.5 | high | A | 26.488713 | 21.682401 | 30.870333 |
| 3 | 100.0 | 3.5 | low | A | 19.816026 | 16.520639 | 23.370692 |
| 4 | 100.0 | 3.5 | medium | A | 18.033880 | 15.754388 | 20.591446 |
| 5 | 100.0 | 3.5 | high | A | 19.002172 | 15.638381 | 22.185714 |
| 6 | 120.0 | 1.5 | low | A | 26.052900 | 21.968129 | 30.092588 |
| 7 | 120.0 | 1.5 | medium | A | 24.270754 | 20.375174 | 28.660645 |
| 8 | 120.0 | 1.5 | high | A | 25.239046 | 20.935151 | 29.297051 |
| 9 | 120.0 | 3.5 | low | A | 19.219721 | 15.631405 | 22.792257 |
| 10 | 120.0 | 3.5 | medium | A | 17.437575 | 15.096732 | 19.889231 |
| 11 | 120.0 | 3.5 | high | A | 18.405867 | 15.498032 | 20.902462 |
When a dictionary is passed, that informs Bambi that the user wants to compute predictions on user provided values. Thus, a pairwise grid is constructed using the dictionary values. Otherwise, a dataframe of unequal array lengths cannot be constructed. Furthermore, since gear was not passed as a key, but was a term in the model, the default value of A was computed for it.
Given we now know that a pairwise grid was computed usiong the conditional dict, One interpretation of the plot above is that across all cylinder groups, a larger wt results in a lower mean mpg.
Unit level predictions
In the previous example, user provided values were computed to construct a pairwise grid to compute the conditional adjusted predictions. It is also possible to compute predictions using the observed (empirical) data used to fit the model and then average over a specific or set of covariates to obtain average adjusted predictions. This is known as unit level predictions. To compute unit level predictions, do not pass any values to the conditional arg. and or specify None (the default).
result = bmb.interpret.predictions(
model,
idata,
conditional=None
)
result.summary.head()| cyl | gear | hp | wt | estimate | lower_3.0% | upper_97.0% | |
|---|---|---|---|---|---|---|---|
| 0 | medium | B | 110.0 | 2.620 | 22.235413 | 20.137992 | 24.374622 |
| 1 | medium | B | 110.0 | 2.875 | 21.322531 | 19.262133 | 23.233959 |
| 2 | low | B | 93.0 | 2.320 | 25.926058 | 24.242364 | 27.590406 |
| 3 | medium | A | 110.0 | 3.215 | 18.756008 | 16.329689 | 21.104195 |
| 4 | high | A | 175.0 | 3.440 | 16.917122 | 15.331732 | 18.602223 |
# data used to fit the model
model.data[["cyl", "gear", "hp", "wt"]].head()| cyl | gear | hp | wt | |
|---|---|---|---|---|
| 0 | medium | B | 110.0 | 2.620 |
| 1 | medium | B | 110.0 | 2.875 |
| 2 | low | B | 93.0 | 2.320 |
| 3 | medium | A | 110.0 | 3.215 |
| 4 | high | A | 175.0 | 3.440 |
Notice how the data in the summary dataframe and model data are the same.
Marginalizing over covariates
Since the empirical distrubution is used for computing predictions, the same number of rows (\(32\)) is returned as the data used to fit the model. To average over a covariate, use the average_by argument. If all is passed, then predictions averages over all covariates and a single estimate is returned. Else, if a single or list of covariates are passed, then predictions averages by the covariates passed.
result = bmb.interpret.predictions(
model,
idata,
conditional=None,
average_by="all"
)
result.summary| estimate | lower_3.0% | upper_97.0% | |
|---|---|---|---|
| 0 | 20.065272 | 17.898009 | 22.21864 |
Average by subgroups
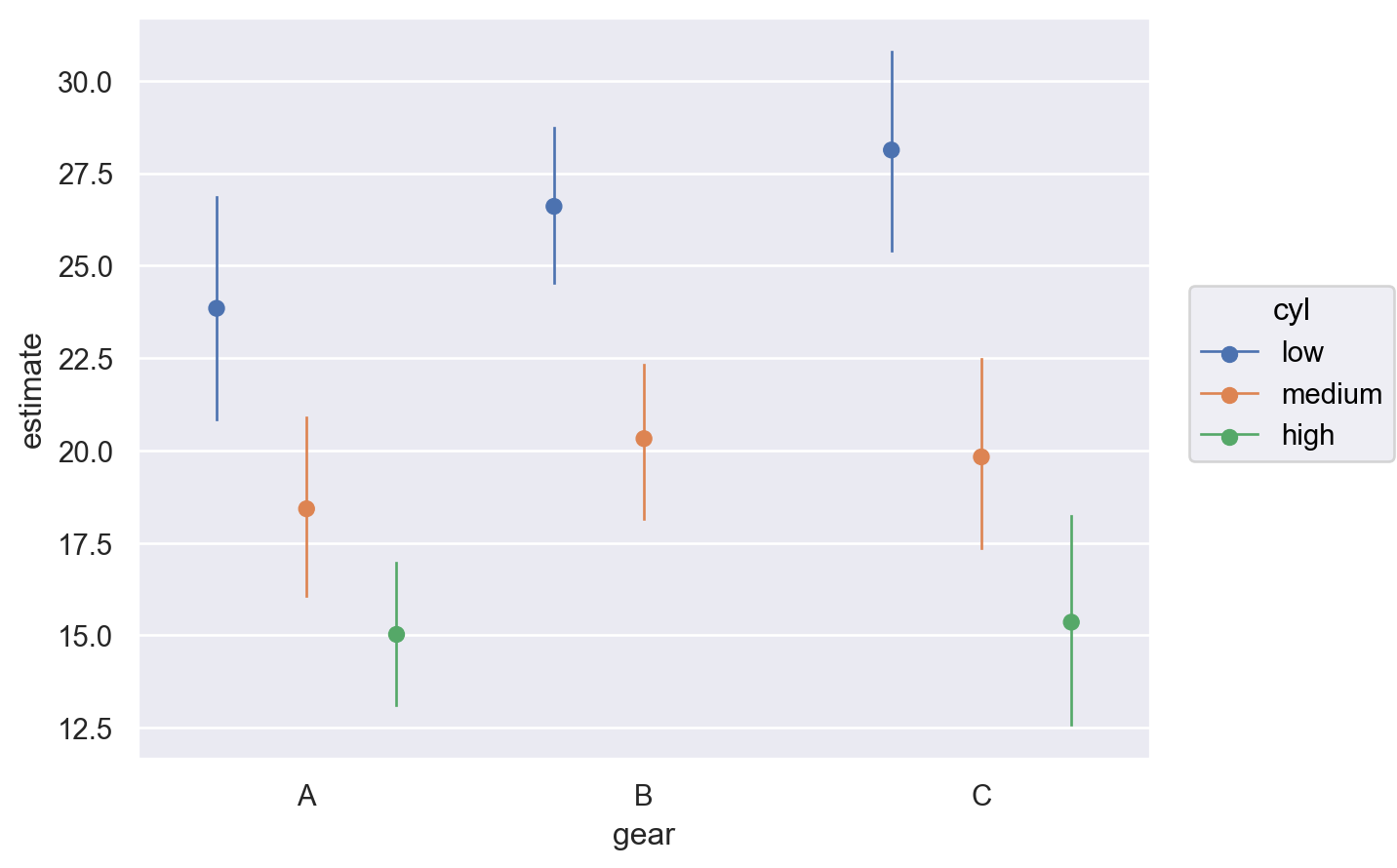
It is still possible to plot predictions when computing unit level predictions. However, now a covariate(s) must be passed to average_by to obtain average adjusted predictions by group. In the plot below, we obtain average predictions grouped by gear and cyl.
bmb.interpret.plot_predictions(
model,
idata,
conditional=None,
average_by=["gear", "cyl"],
)
Negative Binomial Model
Lets move onto a model that uses a distribution that is a member of the exponential distribution family and utilizes a link function. For this, we will implement the Negative binomial model from the students absences example. School administrators study the attendance behavior of high school juniors at two schools. Predictors of the number of days of absence include the type of program in which the student is enrolled and a standardized test in math. We have attendance data on 314 high school juniors. The variables of insterest in the dataset are the following:
- daysabs: The number of days of absence. It is our response variable.
- progr: The type of program. Can be one of ‘General’, ‘Academic’, or ‘Vocational’.
- math: Score in a standardized math test.
# Load data, define and fit Bambi model
data = pd.read_stata("https://stats.idre.ucla.edu/stat/stata/dae/nb_data.dta")
data["prog"] = data["prog"].map({1: "General", 2: "Academic", 3: "Vocational"})
model_interaction = bmb.Model(
"daysabs ~ 0 + prog + scale(math) + prog:scale(math)",
data,
family="negativebinomial"
)
idata_interaction = model_interaction.fit(
draws=1000, target_accept=0.95, random_seed=1234, chains=4
)Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [alpha, prog, scale(math), prog:scale(math)]Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 1 seconds.This model utilizes a log link function and a negative binomial distribution for the likelihood. Also note that this model also contains an interaction prog:sale(math).
model_interaction Formula: daysabs ~ 0 + prog + scale(math) + prog:scale(math)
Family: negativebinomial
Link: mu = log
Observations: 314
Priors:
target = mu
Common-level effects
prog ~ Normal(mu: [0. 0. 0.], sigma: [5.0102 7.4983 5.2746])
scale(math) ~ Normal(mu: 0.0, sigma: 2.5)
prog:scale(math) ~ Normal(mu: [0. 0.], sigma: [6.1735 4.847 ])
Auxiliary parameters
alpha ~ HalfCauchy(beta: 1.0)
------
* To see a plot of the priors call the .plot_priors() method.
* To see a summary or plot of the posterior pass the object returned by .fit() to az.summary() or az.plot_trace()bmb.interpret.plot_predictions(
model_interaction,
idata_interaction,
"math"
)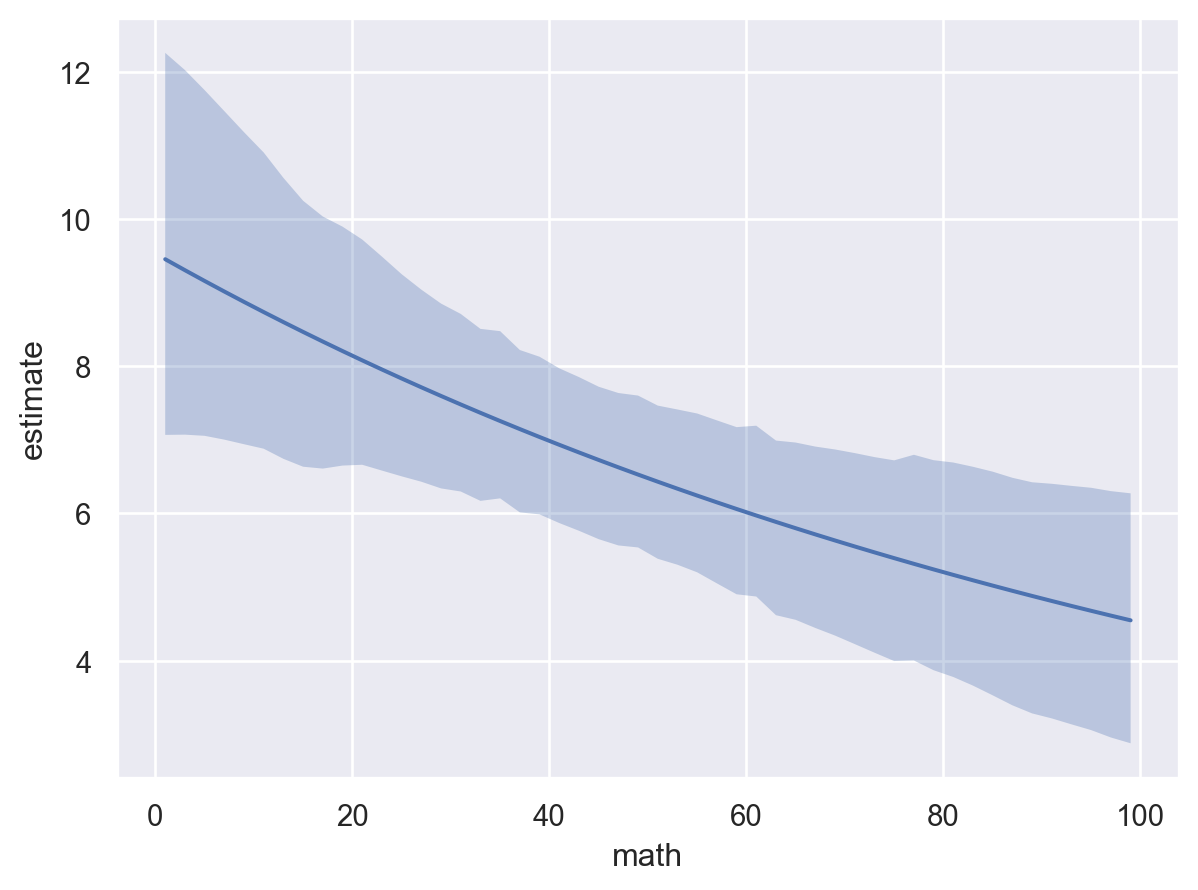
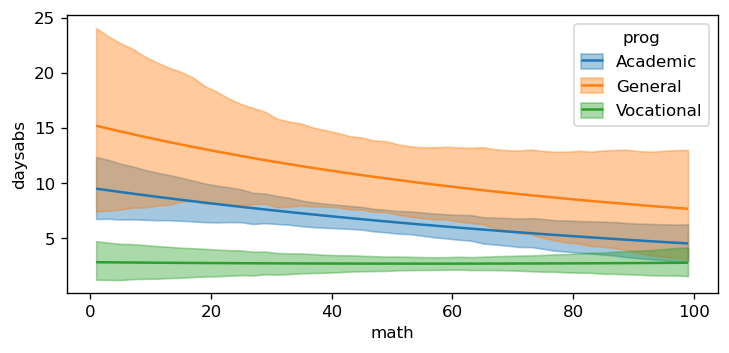
The plot above shows that as math increases, the mean daysabs decreases. However, as the model contains an interaction term, the effect of math on daysabs depends on the value of prog. Therefore, we will use plot_predictions to plot the conditional adjusted predictions for each level of prog.
bmb.interpret.plot_predictions(
model_interaction,
idata_interaction,
["math", "prog"]
)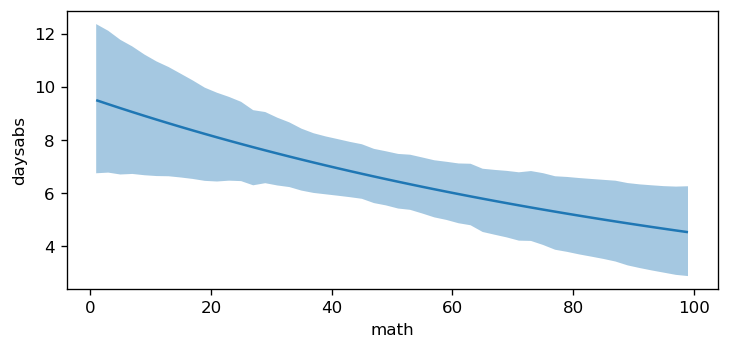
Passing specific subplot_kwargs can allow for a more interpretable plot. Especially when the posterior predictive distribution plot results in overlapping credible intervals.
bmb.interpret.plot_predictions(
model_interaction,
idata_interaction,
conditional=["math", "prog"],
target="daysabs",
subplot_kwargs={"main": "math", "group": "prog", "panel": "prog"},
fig_kwargs={"theme": {"figure.figsize": (8, 4)}}
)
Logistic Regression
To further demonstrate the plot_predictions function, we will implement a logistic regression model. This example is taken from the marginaleffects plot_predictions documentation. The internet movie database, http://imdb.com/, is a website devoted to collecting movie data supplied by studios and fans. It claims to be the biggest movie database on the web and is run by Amazon. The movies in this dataset were selected for inclusion if they had a known length and had been rated by at least one imdb user. The dataset below contains 28,819 rows and 24 columns. The variables of interest in the dataset are the following: - title. Title of the movie. - year. Year of release. - budget. Total budget (if known) in US dollars - length. Length in minutes. - rating. Average IMDB user rating. - votes. Number of IMDB users who rated this movie. - r1-10. Multiplying by ten gives percentile (to nearest 10%) of users who rated this movie a 1. - mpaa. MPAA rating. - action, animation, comedy, drama, documentary, romance, short. Binary variables represent- ing if movie was classified as belonging to that genre.
data = pd.read_csv("https://vincentarelbundock.github.io/Rdatasets/csv/ggplot2movies/movies.csv")
data["style"] = "Other"
data.loc[data["Action"] == 1, "style"] = "Action"
data.loc[data["Comedy"] == 1, "style"] = "Comedy"
data.loc[data["Drama"] == 1, "style"] = "Drama"
data["certified_fresh"] = (data["rating"] >= 8) * 1
data = data[data["length"] < 240]
data["length"] = data["length"].astype(float)
model = bmb.Model("certified_fresh ~ 0 + scale(length) * style", data=data, family="bernoulli")
idata = model.fit(inference_method="nutpie")Modeling the probability that certified_fresh==1Sampler Progress
Total Chains: 4
Active Chains: 0
Finished Chains: 4
Sampling for a minute
Estimated Time to Completion: now
| Progress | Draws | Divergences | Step Size | Gradients/Draw |
|---|---|---|---|---|
| 2000 | 0 | 0.38 | 7 | |
| 2000 | 0 | 0.34 | 15 | |
| 2000 | 0 | 0.36 | 7 | |
| 2000 | 0 | 0.40 | 15 |
The logistic regression model uses a logit link function and a Bernoulli likelihood. Therefore, the link scale is the log-odds of a successful response and the response scale is the probability of a successful response.
model Formula: certified_fresh ~ 0 + scale(length) * style
Family: bernoulli
Link: p = logit
Observations: 58662
Priors:
target = p
Common-level effects
scale(length) ~ Normal(mu: 0.0, sigma: 1.0)
style ~ Normal(mu: [0. 0. 0. 0.], sigma: [1. 1. 1. 1.])
scale(length):style ~ Normal(mu: [0. 0. 0.], sigma: [1.0143 1.0143 1.0143])
------
* To see a plot of the priors call the .plot_priors() method.
* To see a summary or plot of the posterior pass the object returned by .fit() to az.summary() or az.plot_trace()Again, by default, the plot_predictions function plots the mean outcome on the response scale. Therefore, the plot below shows the probability of a successful response certified_fresh as a function of length.
bmb.interpret.plot_predictions(model, idata, "length")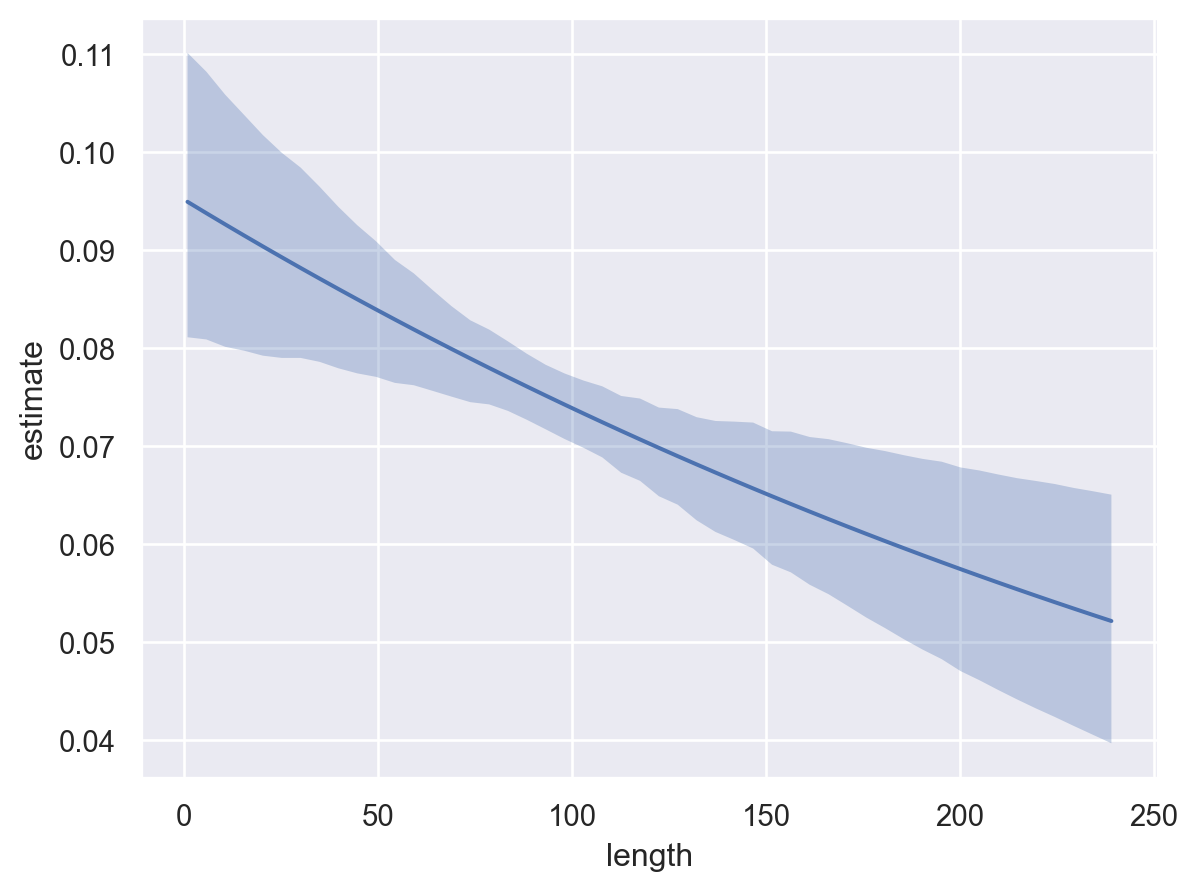
Additionally, we can see how the probability of certified_fresh varies as a function of categorical covariates.
bmb.interpret.plot_predictions(model, idata, "style")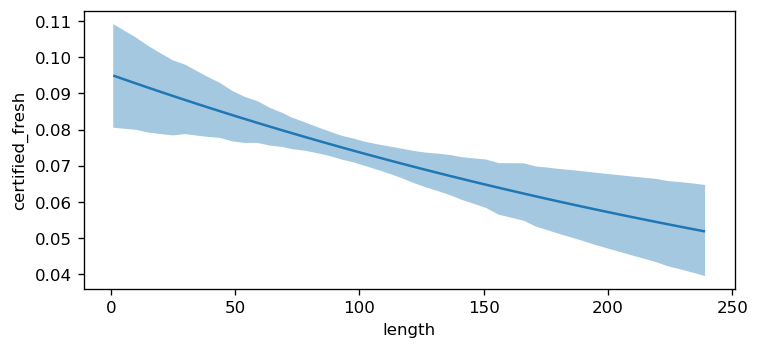
Plotting other model parameters
plot_predictions also has the argument target where target determines what parameter of the response distribution is plotted as a function of the explanatory variables. This argument is useful in distributional models, i.e., when the response distribution contains a parameter for location, scale and or shape. The default value is "mean", which plots the mean parameter of the response distribution. Setting target="mpg" plots the posterior predictive distribution, which refers to the full response variable rather than any individual parameter. For this example, we will simulate our own dataset.
rng = np.random.default_rng(121195)
N = 200
a, b = 0.5, 1.1
x = rng.uniform(-1.5, 1.5, N)
shape = np.exp(0.3 + x * 0.5 + rng.normal(scale=0.1, size=N))
y = rng.gamma(shape, np.exp(a + b * x) / shape, N)
data_gamma = pd.DataFrame({"x": x, "y": y})
formula = bmb.Formula("y ~ x", "alpha ~ x")
model = bmb.Model(formula, data_gamma, family="gamma")
idata = model.fit(random_seed=1234)Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [Intercept, x, alpha_Intercept, alpha_x]Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 1 seconds.
There were 4 divergences after tuning. Increase `target_accept` or reparameterize.model Formula: y ~ x
alpha ~ x
Family: gamma
Link: mu = inverse
alpha = log
Observations: 200
Priors:
target = mu
Common-level effects
Intercept ~ Normal(mu: 0.0, sigma: 2.5037)
x ~ Normal(mu: 0.0, sigma: 2.8025)
target = alpha
Common-level effects
alpha_Intercept ~ Normal(mu: 0.0, sigma: 1.0)
alpha_x ~ Normal(mu: 0.0, sigma: 1.0)
------
* To see a plot of the priors call the .plot_priors() method.
* To see a summary or plot of the posterior pass the object returned by .fit() to az.summary() or az.plot_trace()The model we defined uses a gamma distribution parameterized by alpha and mu where alpha utilizes a log link and mu goes through an inverse link. Therefore, we can plot either: (1) the mu of the response distribution (which is the default), or (2) alpha of the response distribution as a function of the explanatory variable \(x\).
# First, the mean of the response (default)
bmb.interpret.plot_predictions(model, idata, "x")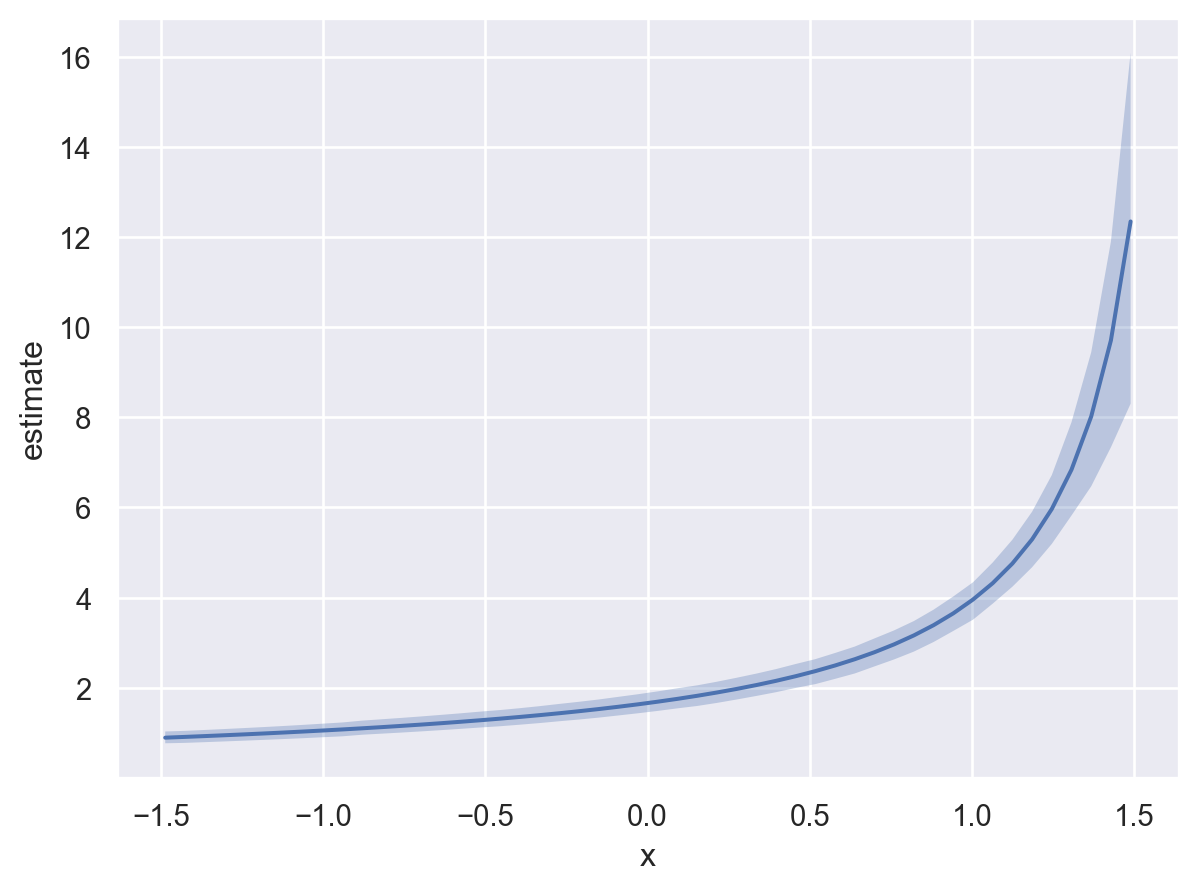
Below, instead of plotting the default target (target="mean"), we set target="alpha" to visualize how the model parameter alpha varies as a function of the x predictor.
# Second, another param. of the distribution: alpha
bmb.interpret.plot_predictions(model, idata, "x", target="alpha")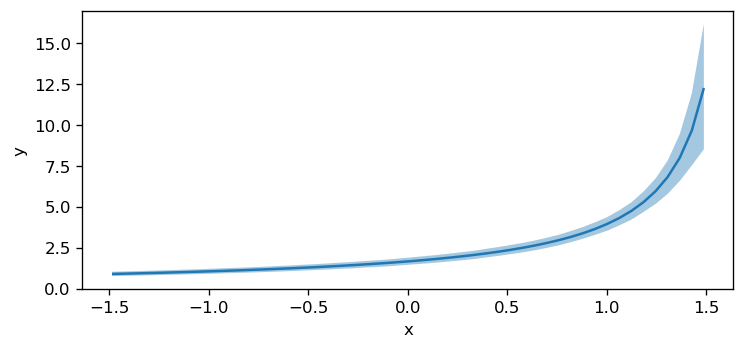
%load_ext watermark
%watermark -n -u -v -iv -wLast updated: Mon, 16 Mar 2026
Python implementation: CPython
Python version : 3.13.12
IPython version : 9.10.0
bambi : 0.1.dev891+g05567136c.d20260223
matplotlib: 3.10.8
numpy : 2.3.5
pandas : 2.3.3
Watermark: 2.6.0