import warnings
import arviz as az
import bambi as bmb
import matplotlib.pyplot as plt
import matplotlib.lines as mlines
import numpy as np
import pandas as pd
import seaborn as sns
# Disable a FutureWarning in ArviZ at the moment of running the notebook
az.style.use("arviz-darkgrid")
warnings.simplefilter(action='ignore', category=FutureWarning)Logistic Regression and Model Comparison with Bambi and ArviZ
Adults dataset
The adults dataset is comprised of census data from 1994 in United States.
The goal is to use demographic variables to predict whether an individual makes more than $50,000 per year.
The following is a description of the variables in the dataset.
- age: Individual’s age
- workclass: Labor class.
- fnlwgt: It is not specified, but we guess it is a final sampling weight.
- education: Education level as a categorical variable.
- educational_num: Education level as numerical variable. It does not reflect years of education.
- marital_status: Marital status.
- occupation: Occupation.
- relationship: Relationship with the head of household.
- race: Individual’s race.
- sex: Individual’s sex.
- capital_gain: Capital gain during unspecified period of time.
- capital_loss: Capital loss during unspecified period of time.
- hs_week: Hours of work per week.
- native_country: Country of birth.
- income: Income as a binary variable (either below or above 50K per year).
We are only using the following variables in this example: income, sex, race, age, and hs_week. This subset is comprised of both categorical and numerical variables which allows us to visualize how to incorporate both types in a logistic regression model while helping to keep the analysis simpler.
data = bmb.load_data("adults")
data.info()
data.head()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 32561 entries, 0 to 32560
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 income 32561 non-null object
1 sex 32561 non-null object
2 race 32561 non-null object
3 age 32561 non-null int64
4 hs_week 32561 non-null int64
dtypes: int64(2), object(3)
memory usage: 1.2+ MB| income | sex | race | age | hs_week | |
|---|---|---|---|---|---|
| 0 | <=50K | Male | White | 39 | 40 |
| 1 | <=50K | Male | White | 50 | 13 |
| 2 | <=50K | Male | White | 38 | 40 |
| 3 | <=50K | Male | Black | 53 | 40 |
| 4 | <=50K | Female | Black | 28 | 40 |
Categorical variables are presented as from type object. In this step we convert them to category.
data["age"] = data["age"].astype("float")
categorical_cols = data.columns[data.dtypes == object].tolist()
for col in categorical_cols:
data[col] = data[col].astype("category")
data.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 32561 entries, 0 to 32560
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 income 32561 non-null category
1 sex 32561 non-null category
2 race 32561 non-null category
3 age 32561 non-null float64
4 hs_week 32561 non-null int64
dtypes: category(3), float64(1), int64(1)
memory usage: 604.7 KBInstead of going straight to fitting models, we’re going to do a some exploratory analysis of the variables in the dataset. First we have some plots, and then some conclusions about the information in the plots.
# Just a utilitary function to truncate labels and avoid overlapping in plots
def truncate_labels(ticklabels, width=8):
def truncate(label, width):
if len(label) > width - 3:
return label[0 : (width - 4)] + "..."
else:
return label
labels = [x.get_text() for x in ticklabels]
labels = [truncate(lbl, width) for lbl in labels]
return labelsfig, axes = plt.subplots(3, 2, figsize=(12, 15))
sns.countplot(x="income", color="C0", data=data, ax=axes[0, 0], saturation=1)
sns.countplot(x="sex", color="C0", data=data, ax=axes[0, 1], saturation=1);
sns.countplot(x="race", color="C0", data=data, ax=axes[1, 0], saturation=1);
axes[1, 0].set_xticklabels(truncate_labels(axes[1, 0].get_xticklabels()))
axes[1, 1].hist(data["age"], bins=20);
axes[1, 1].set_xlabel("Age")
axes[1, 1].set_ylabel("Count")
axes[2, 0].hist(data["hs_week"], bins=20);
axes[2, 0].set_xlabel("Hours of work / week")
axes[2, 0].set_ylabel("Count")
axes[2, 1].axis('off');/tmp/ipykernel_29412/1570134311.py:5: UserWarning: set_ticklabels() should only be used with a fixed number of ticks, i.e. after set_ticks() or using a FixedLocator.
axes[1, 0].set_xticklabels(truncate_labels(axes[1, 0].get_xticklabels()))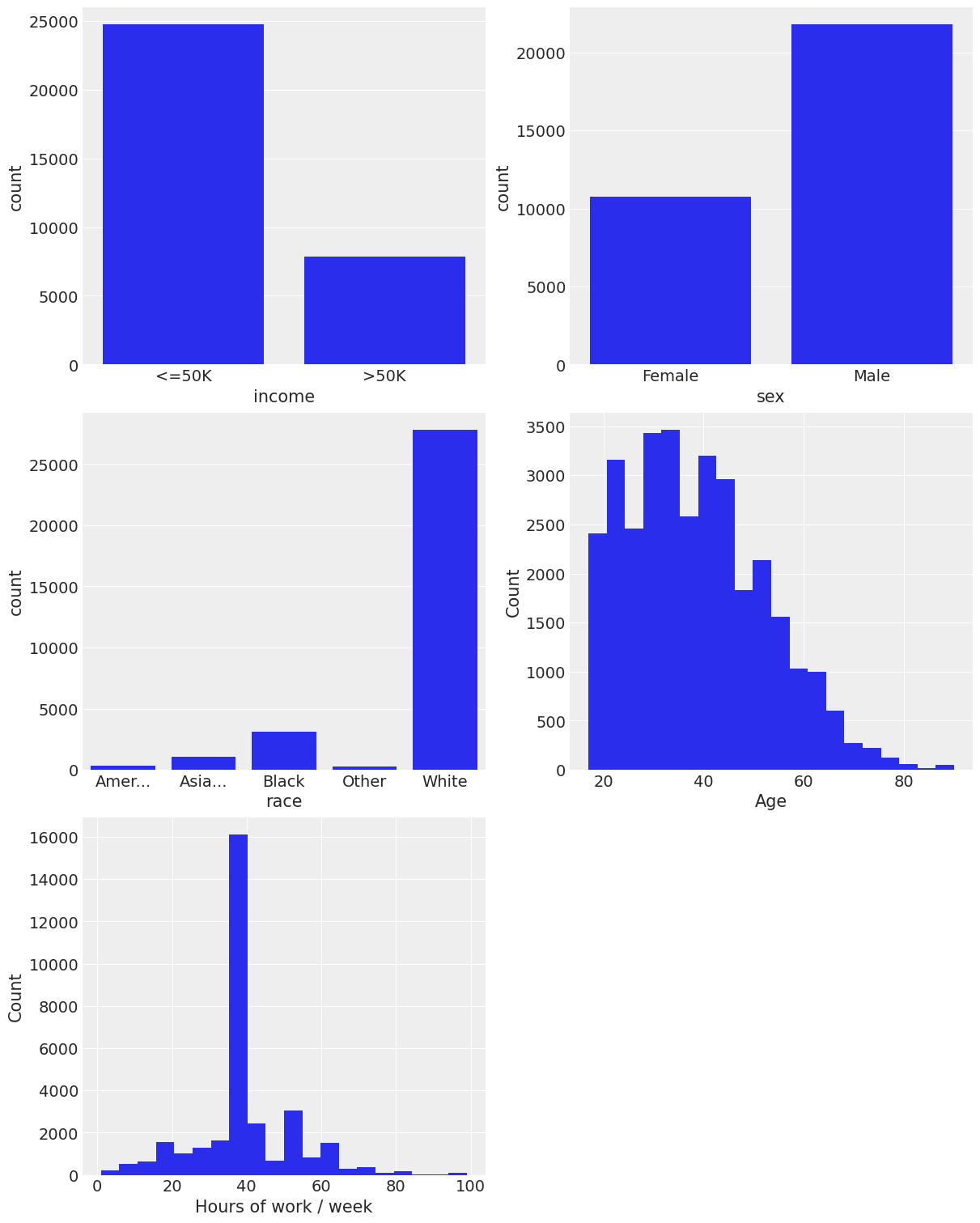
Highlights
- Approximately 25% of the people make more than 50K a year.
- Two thirds of the subjects are males.
- The great majority of the subjects are white, only a minority are black and the other categories are very infrequent.
- The distribution of age is skewed to the right, as one might expect.
- The distribution of hours of work per week looks weird at first sight. But what is a typical workload per week? You got it, 40 hours :).
We only keep the races black and white to simplify the analysis. The other categories don’t appear very often in our data.
Now, we see the distribution of income for the different levels of our explanatory variables. Numerical variables are binned to make the analysis possible.
data = data[data["race"].isin(["Black", "White"])]
data["race"] = data["race"].cat.remove_unused_categories()
age_bins = [17, 25, 35, 45, 65, 90]
data["age_binned"] = pd.cut(data["age"], age_bins)
hours_bins = [0, 20, 40, 60, 100]
data["hs_week_binned"] = pd.cut(data["hs_week"], hours_bins)fig, axes = plt.subplots(3, 2, figsize=(12, 15))
sns.countplot(x="income", color="C0", data=data, ax=axes[0, 0])
sns.countplot(x="sex", hue="income", data=data, ax=axes[0, 1])
sns.countplot(x="race", hue="income", data=data, ax=axes[1, 0])
sns.countplot(x="age_binned", hue="income", data=data, ax=axes[1, 1])
sns.countplot(x="hs_week_binned", hue="income", data=data, ax=axes[2, 0])
axes[2, 1].axis("off");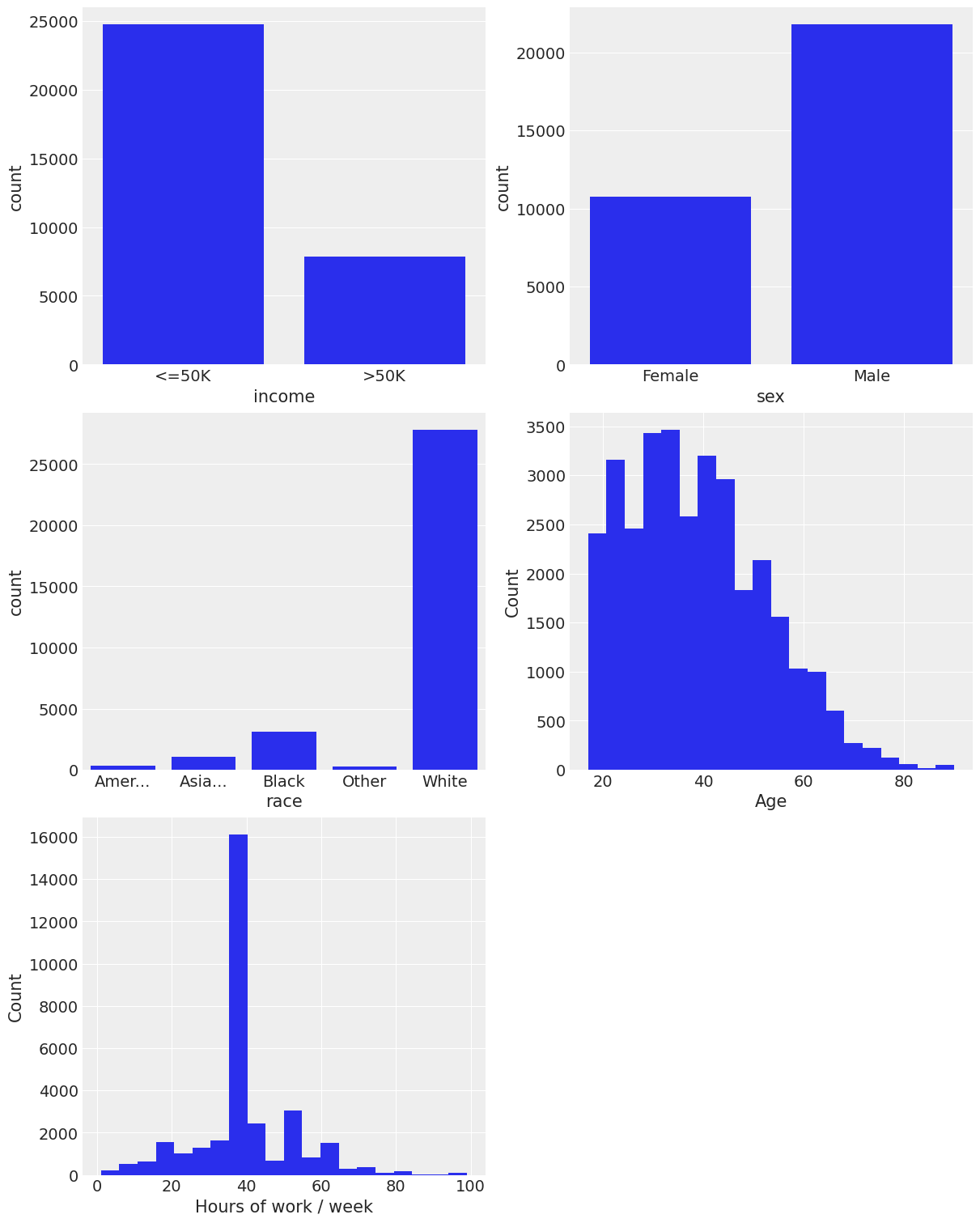
Some quick and gross info from the plots
- The probability of making more than $50k a year is larger if you are a Male.
- A person also has more probability of making more than $50k/yr if she/he is White.
- For age, we see the probability of making more than $50k a year increases as the variable increases, up to a point where it starts to decrease.
- Also, the more hours a person works per week, the higher the chance of making more than $50k/yr. There’s a big jump in that probability when the hours of work per week jump from the (20, 40] bin to the (40, 60] one.
The model
We will use a logistic regression model to estimate the probability of making more than \$50K as a function of age, hours of work per week, sex, race and education level.
If we have a binary response variable \(Y\) and a set of predictors or explanatory variables \(X_1, X_2, \cdots, X_p\) the logistic regression model can be defined as follows:
\[\log{\left(\frac{\pi}{1 - \pi}\right)} = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \cdots + \beta_p X_p\]
where \(\pi = P(Y = 1)\) (a.k.a. probability of success) and \(\beta_0, \beta_1, \cdots \beta_p\) are unknown parameters. The term on the left side is the logarithm of the odds ratio or simply known as the log-odds. With little effort, the expression can be re-arranged to express our probability of interest, \(\pi\), as a function of the betas and the predictors.
\[ \pi = \frac{e^{\beta_0 + \beta_1 X_1 + \cdots + \beta_p X_p}}{1 + e^{\beta_0 + \beta_1 X_1 + \cdots + \beta_p X_p}} = \frac{1}{1 + e^{-(\beta_0 + \beta_1 X_1 + \cdots + \beta_p X_p)}} \]
We need to specify a prior and a likelihood in order to draw samples from the posterior distribution. We could use sociological knowledge about the effects of age and education on income, but instead, let’s use the default prior specification in Bambi.
The likelihood is the product of \(n\) Bernoulli trials, \(\prod_{i=1}^{n}{p_i^y(1-p_i)^{1-y_i}}\) where \(p_i = P(Y=1)\).
In our case, we have
\[Y = \left\{ \begin{array}{ll} 1 & \textrm{if the person makes more than 50K per year} \\ 0 & \textrm{if the person makes less than 50K per year} \end{array} \right. \]
\[\pi = P(Y=1)\]
But this is a Bambi example, right? Let’s see how Bambi can helps us to build a logistic regression model.
Model 1:
\[ \log{\left(\frac{\pi}{1 - \pi}\right)} = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \beta_3 X_3 + \beta_4 X_4 \]
Where:
\[ \begin{split} X_1 &= \displaystyle \frac{\text{Age} - \text{mean(Age)}}{\text{std(Age)}} \\ X_2 &= \displaystyle \frac{\text{Hours week} - \text{mean(Hours week)}}{\text{std(Hours week)}} \\ X_3 &= \left\{ \begin{array}{ll} 1 & \textrm{if the person is male} \\ 0 & \textrm{if the person is female} \end{array} \right. \\ X_4 &= \left\{ \begin{array}{ll} 1 & \textrm{if the person is white} \\ 0 & \textrm{if the person is black} \end{array} \right. \end{split} \]
model1 = bmb.Model(
"income['>50K'] ~ sex + race + scale(age) + scale(hs_week)",
data,
family="bernoulli"
)
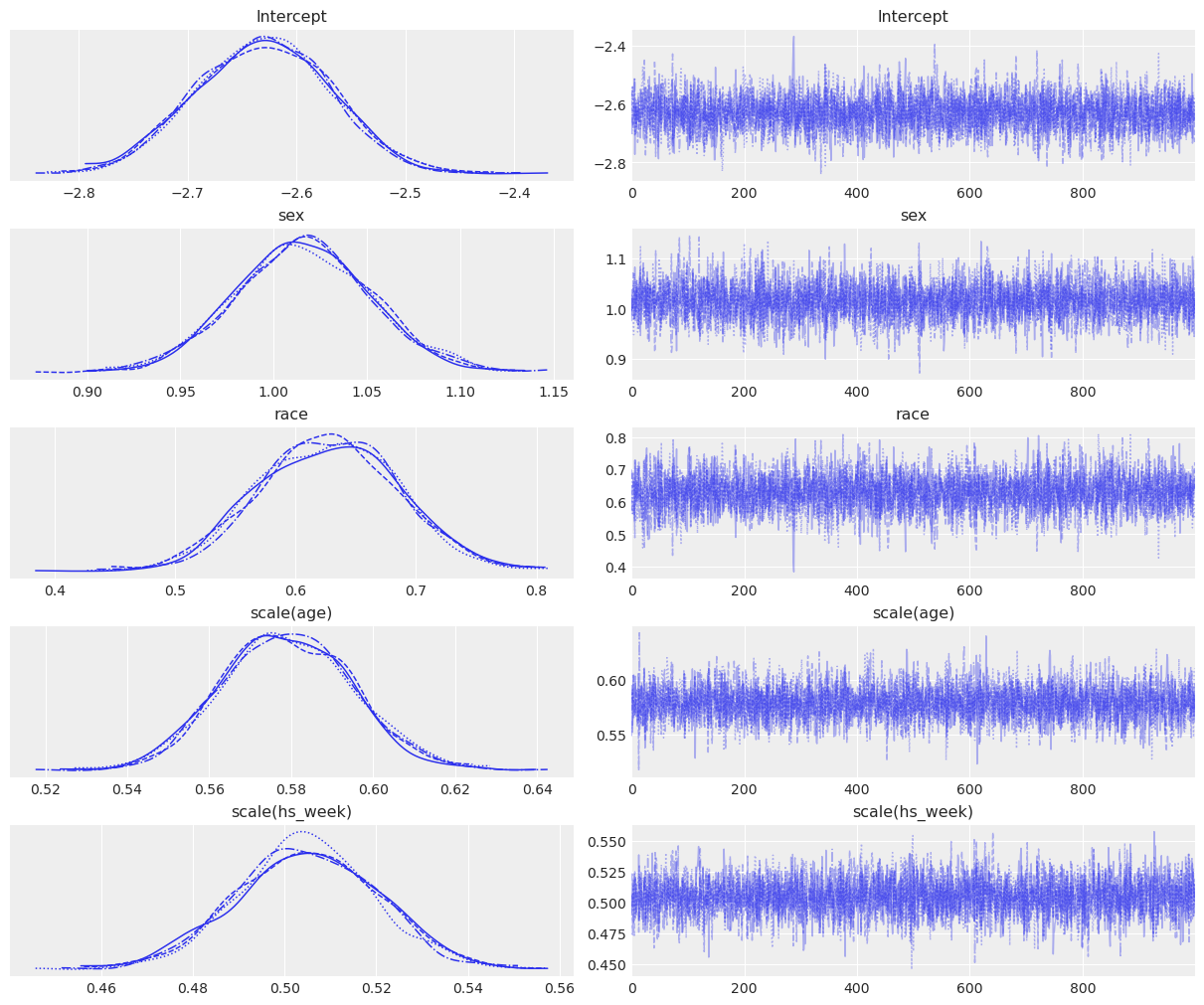
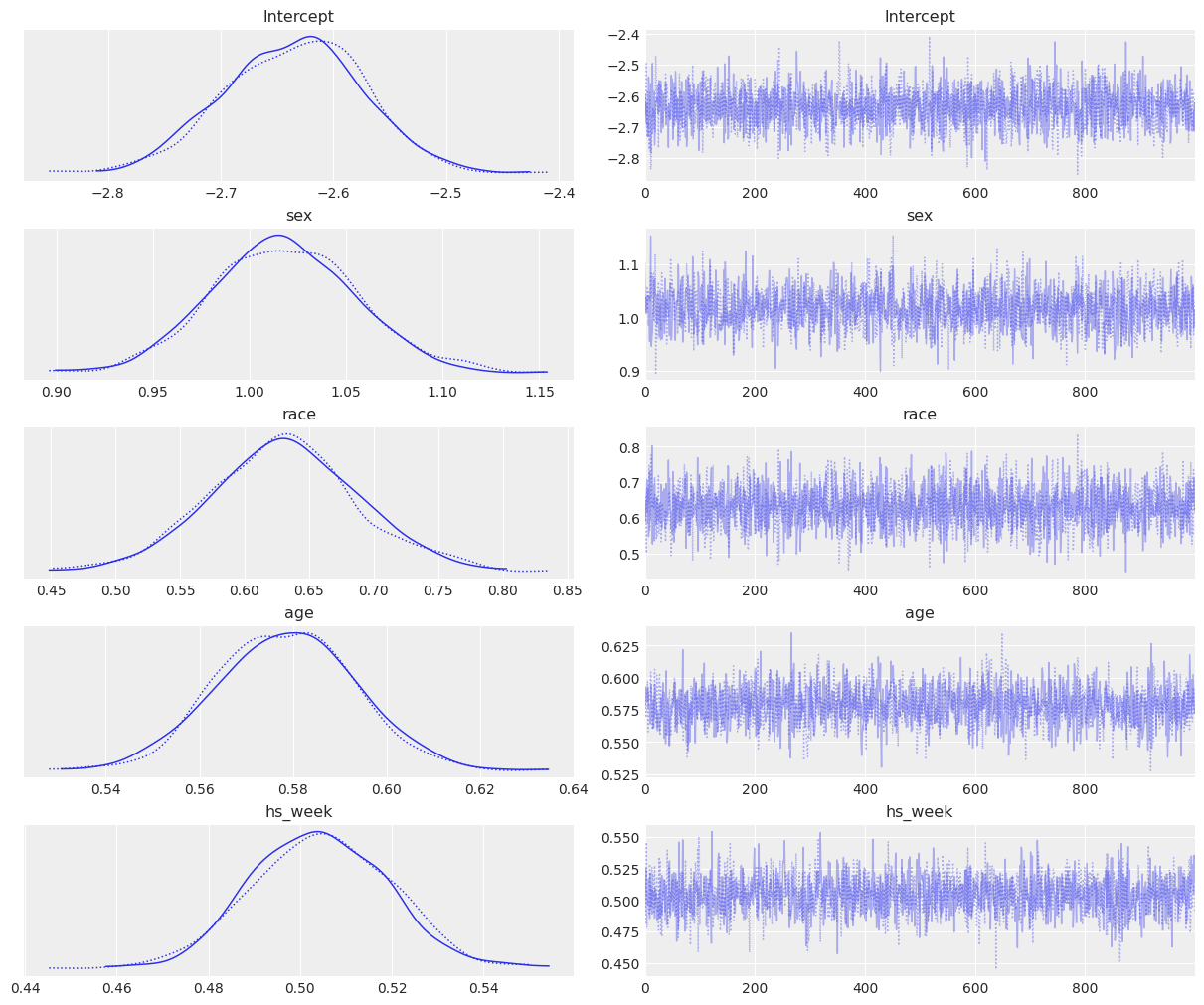
fitted1 = model1.fit(inference_method="numpyro", idata_kwargs={"log_likelihood": True})Modeling the probability that income==>50Kaz.plot_trace(fitted1);
az.summary(fitted1)| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| Intercept | -2.630 | 0.062 | -2.750 | -2.524 | 0.001 | 0.001 | 4137.0 | 3083.0 | 1.0 |
| sex[Male] | 1.016 | 0.037 | 0.941 | 1.080 | 0.001 | 0.001 | 4431.0 | 3131.0 | 1.0 |
| race[White] | 0.628 | 0.058 | 0.519 | 0.734 | 0.001 | 0.001 | 4285.0 | 2995.0 | 1.0 |
| scale(age) | 0.579 | 0.016 | 0.550 | 0.608 | 0.000 | 0.000 | 4761.0 | 2891.0 | 1.0 |
| scale(hs_week) | 0.505 | 0.015 | 0.476 | 0.533 | 0.000 | 0.000 | 4973.0 | 3192.0 | 1.0 |
Model 2
\[ \log{\left(\frac{\pi}{1 - \pi}\right)} = \beta_0 + \beta_1 X_1 + \beta_2 X_1^2 + \beta_3 X_2 + \beta_4 X_2^2 + \beta_5 X_3 + \beta_6 X_4 \]
Where:
\[ \begin{aligned} X_1 &= \displaystyle \frac{\text{Age} - \text{mean(Age)}}{\text{std(Age)}} \\ X_2 &= \displaystyle \frac{\text{Hours week} - \text{mean(Hours week)}}{\text{std(Hours week)}} \\ X_3 &= \left\{ \begin{array}{ll} 1 & \textrm{if the person is male} \\ 0 & \textrm{if the person is female} \end{array} \right. \\ X_4 &= \left\{ \begin{array}{ll} 1 & \textrm{if the person is white} \\ 0 & \textrm{if the person is black} \end{array} \right. \\ \end{aligned} \]
model2 = bmb.Model(
"income['>50K'] ~ sex + race + scale(age) + I(scale(age) ** 2) + scale(hs_week) + I(scale(hs_week) ** 2)",
data,
family="bernoulli"
)
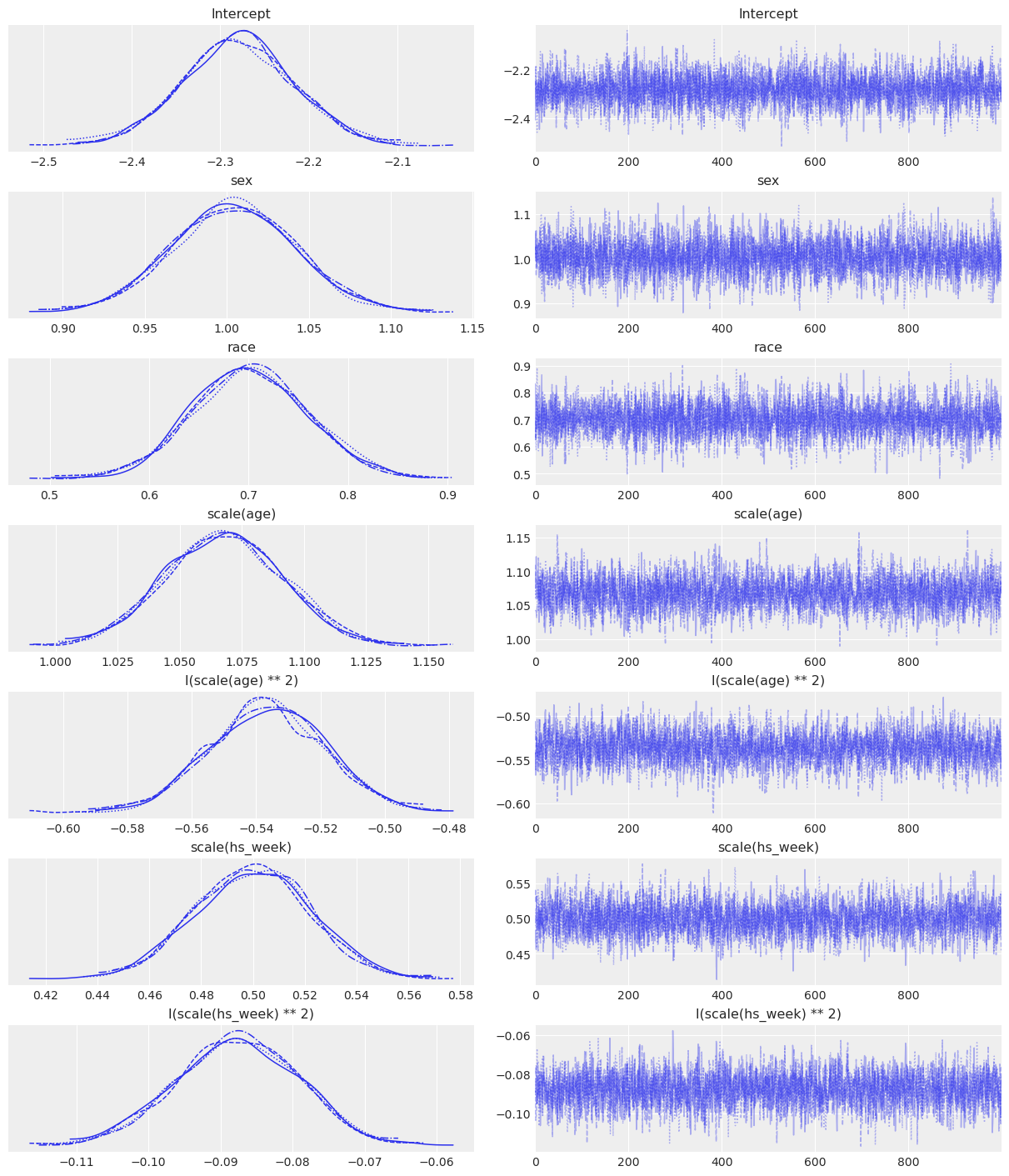
fitted2 = model2.fit(inference_method="numpyro", idata_kwargs={"log_likelihood": True})Modeling the probability that income==>50Kaz.plot_trace(fitted2);
az.summary(fitted2)| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| Intercept | -2.281 | 0.064 | -2.399 | -2.161 | 0.001 | 0.001 | 4789.0 | 3303.0 | 1.0 |
| sex[Male] | 1.004 | 0.038 | 0.933 | 1.075 | 0.001 | 0.001 | 4552.0 | 3072.0 | 1.0 |
| race[White] | 0.701 | 0.059 | 0.589 | 0.812 | 0.001 | 0.001 | 4544.0 | 3160.0 | 1.0 |
| scale(age) | 1.068 | 0.024 | 1.022 | 1.110 | 0.000 | 0.000 | 2884.0 | 2919.0 | 1.0 |
| I(scale(age) ** 2) | -0.537 | 0.018 | -0.570 | -0.503 | 0.000 | 0.000 | 2911.0 | 2982.0 | 1.0 |
| scale(hs_week) | 0.500 | 0.022 | 0.459 | 0.542 | 0.000 | 0.000 | 3497.0 | 2973.0 | 1.0 |
| I(scale(hs_week) ** 2) | -0.088 | 0.009 | -0.104 | -0.072 | 0.000 | 0.000 | 3815.0 | 3584.0 | 1.0 |
Model 3
\[ \log{\left(\frac{\pi}{1 - \pi}\right)} = \beta_0 + \beta_1 X_1 + \beta_2 X_1^2 + \beta_3 X_1^3 + \beta_4 X_2 + \beta_5 X_2^2 + \beta_6 X_2^3 + \beta_7 X_3 + \beta_8 X_4 \]
Where:
\[ \begin{aligned} X_1 &= \displaystyle \frac{\text{Age} - \text{mean(Age)}}{\text{std(Age)}} \\ X_2 &= \displaystyle \frac{\text{Hours week} - \text{mean(Hours week)}}{\text{std(Hours week)}} \\ X_3 &= \left\{ \begin{array}{ll} 1 & \textrm{if the person is male} \\ 0 & \textrm{if the person is female} \end{array} \right. \\ X_4 &= \left\{ \begin{array}{ll} 1 & \textrm{if the person is white} \\ 0 & \textrm{if the person is black} \end{array} \right. \end{aligned} \]
parts = [
"scale(age)",
"I(scale(age) ** 2)",
"I(scale(age) ** 3)",
"scale(hs_week)",
"I(scale(hs_week) ** 2)",
"I(scale(hs_week) ** 3)",
]
model3 = bmb.Model(
"income['>50K'] ~ sex + race + " + " + ".join(parts),
data,
family="bernoulli"
)
fitted3 = model3.fit(
inference_method="numpyro", random_seed=42, idata_kwargs={"log_likelihood": True}
)Modeling the probability that income==>50Kaz.plot_trace(fitted3);
az.summary(fitted3)| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| Intercept | -2.144 | 0.063 | -2.254 | -2.017 | 0.001 | 0.001 | 4415.0 | 2671.0 | 1.0 |
| sex[Male] | 0.983 | 0.038 | 0.908 | 1.050 | 0.001 | 0.001 | 4241.0 | 2994.0 | 1.0 |
| race[White] | 0.678 | 0.059 | 0.568 | 0.789 | 0.001 | 0.001 | 3936.0 | 2788.0 | 1.0 |
| scale(age) | 0.963 | 0.026 | 0.915 | 1.010 | 0.000 | 0.000 | 3409.0 | 3005.0 | 1.0 |
| I(scale(age) ** 2) | -0.892 | 0.031 | -0.952 | -0.837 | 0.001 | 0.000 | 1953.0 | 2496.0 | 1.0 |
| I(scale(age) ** 3) | 0.174 | 0.011 | 0.153 | 0.195 | 0.000 | 0.000 | 2265.0 | 2289.0 | 1.0 |
| scale(hs_week) | 0.612 | 0.025 | 0.566 | 0.658 | 0.000 | 0.000 | 3769.0 | 3029.0 | 1.0 |
| I(scale(hs_week) ** 2) | -0.010 | 0.010 | -0.030 | 0.009 | 0.000 | 0.000 | 3807.0 | 3296.0 | 1.0 |
| I(scale(hs_week) ** 3) | -0.035 | 0.003 | -0.041 | -0.028 | 0.000 | 0.000 | 3511.0 | 2833.0 | 1.0 |
Model comparison
We can perform a Bayesian model comparison very easily with az.compare(). Here we pass a dictionary with the InferenceData objects that Model.fit() returned and az.compare() returns a data frame that is ordered from best to worst according to the criteria used. By default, ArviZ uses loo, which is an estimation of leave one out cross validation. Another option is the widely applicable information criterion (WAIC). For more information about the information criteria available and other options within the function see the docs.
models_dict = {
"model1": fitted1,
"model2": fitted2,
"model3": fitted3
}
df_compare = az.compare(models_dict)
df_compare| rank | elpd_loo | p_loo | elpd_diff | weight | se | dse | warning | scale | |
|---|---|---|---|---|---|---|---|---|---|
| model3 | 0 | -13987.101214 | 9.611941 | 0.000000 | 1.000000e+00 | 89.258562 | 0.000000 | False | log |
| model2 | 1 | -14154.956552 | 7.998924 | 167.855338 | 1.118893e-07 | 91.283219 | 19.815959 | False | log |
| model1 | 2 | -14915.988458 | 4.983647 | 928.887244 | 0.000000e+00 | 90.971071 | 38.873766 | False | log |
az.plot_compare(df_compare, insample_dev=False);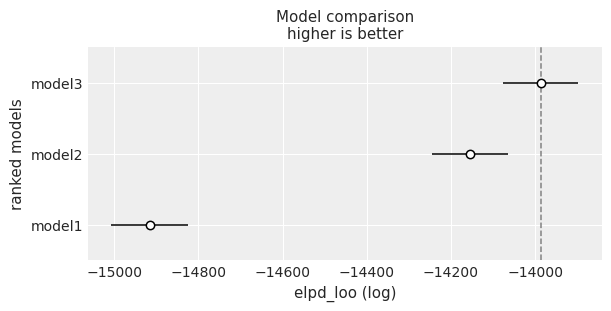
There is a difference in the point estimations (empty circles) between the model with cubic terms (model 3) and the model with quadratic terms (model 2) but there is some overlap between their interval estimations. This time, we are going to select model 2 and do some extra little work with it because from previous experience with this dataset we know there is no substantial difference between them, and model 2 is simpler. However, as we mention in the final remarks, this is not the best you can achieve with this dataset. If you want, you could also try to add other predictors, such as education level and see how it impacts in the model comparison :).
Probability estimation
In this section we plot age vs the probability of making more than 50K a year given different sex and race combinations using plot_predictions from the interpret sub-package.
bmb.interpret.plot_predictions(
model=model2,
idata=fitted2,
conditional={
"age": np.arange(18, 75),
"sex": ["Male", "Female"],
"race": ["Black", "White"],
"hs_week": [40],
},
prob=[0.5, 0.95],
subplot_kwargs={"main": "age", "group": "sex", "panel": "race"},
fig_kwargs={"theme": {"figure.figsize": (9, 5)}, "ylabel": "P(Income > $50K)"}
).layout(extent=[0, 0, 0.875, 1]).show()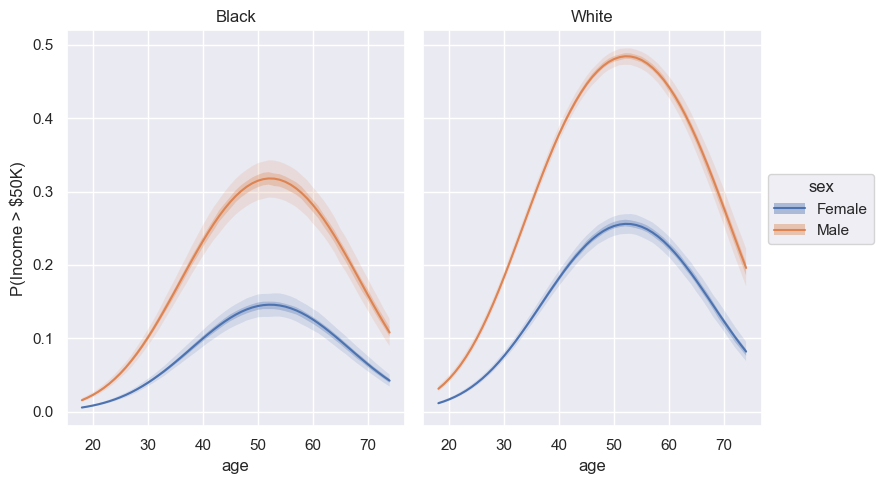
The highest posterior density bands show how the probability of earning more than 50K changes with age for a given profile. In all the cases, we see the probability of making more than $50K increases with age until approximately age 52, when the probability begins to drop off. We can interpret narrow portions of a curve as places where we have low uncertainty and spread out portions of the bands as places where we have somewhat higher uncertainty about our coefficient values.
Final remarks
In this notebook we’ve seen how easy it is to incorporate ArviZ into a Bambi workflow to perform model comparison based on information criteria such as LOO and WAIC. However, an attentive reader might have seen that the highest density interval plot never shows a predicted probability greater than 0.5 (which is not good if we expect to predict that at least some people working 40hrs/wk make more than \$50k/yr). You can increase the hours of work per week for the profiles we’ve used and the HDIs will show larger values. But we won’t be seeing the whole picture.
Although we’re using some demographic variables such as sex and race, the cells resulting from the combinations of their levels are still very heterogeneous. For example, we are mixing individuals of all educational levels. A possible next step is to incorporate education into the different models we compared. If any of the readers (yes, you!) is interested in doing so, here there are some notes that may help
- Education is an ordinal categorical variable with a lot of levels.
- Explore the conditional distribution of income given education levels.
- See what are the counts/proportions of people within each education level.
- Collapse categories (but respect the ordinality!). Try to end up with 5 or less categories if possible.
- Start with a model with only age, sex, race, hs_week and education. Then incorporate higher order terms (second and third powers for example). Don’t go beyond fourth powers.
- Look for a nice activity to do while the sampler does its job.
We know it’s going to take a couple of hours to fit all those models :)
And finally, please feel free to open a new issue if you think there’s something that we can improve.
%load_ext watermark
%watermark -n -u -v -iv -wLast updated: Wed Feb 18 2026
Python implementation: CPython
Python version : 3.13.9
IPython version : 9.6.0
seaborn : 0.13.2
bambi : 0.16.1.dev42+g0d5870261.d20260218
numpy : 2.3.3
matplotlib: 3.10.7
arviz : 0.22.0
pandas : 2.3.3
Watermark: 2.5.0