import arviz as az
import bambi as bmb
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
az.style.use("arviz-darkgrid")
rng = np.random.default_rng(1211)Robust Linear Regression
This example has been lifted from the PyMC Docs, and adapted to for Bambi by Tyler James Burch (@tjburch on GitHub).
Many toy datasets circumvent problems that practitioners run into with real data. Specifically, the assumption of normality can be easily violated by outliers, which can cause havoc in traditional linear regression. One way to navigate this is through robust linear regression, outlined in this example.
First load modules and set the RNG for reproducibility.
Next, generate pseudodata. The bulk of the data will be linear with noise distributed normally, but additionally several outliers will be interjected.
size = 100
true_intercept = 1
true_slope = 2
x = np.linspace(0, 1, size)
# y = a + b*x
true_regression_line = true_intercept + true_slope * x
# add noise
y = true_regression_line + rng.normal(scale=0.5, size=size)
# Add outliers
x_out = np.append(x, [0.1, 0.15, 0.2])
y_out = np.append(y, [8, 6, 9])
data = pd.DataFrame({"x": x_out, "y": y_out})Plot this data. The three data points in the top left are the interjected data.
fig = plt.figure(figsize=(7, 7))
ax = fig.add_subplot(111, xlabel="x", ylabel="y", title="Generated data and underlying model")
ax.plot(x_out, y_out, "x", label="sampled data")
ax.plot(x, true_regression_line, label="true regression line", lw=2.0)
plt.legend(loc=0);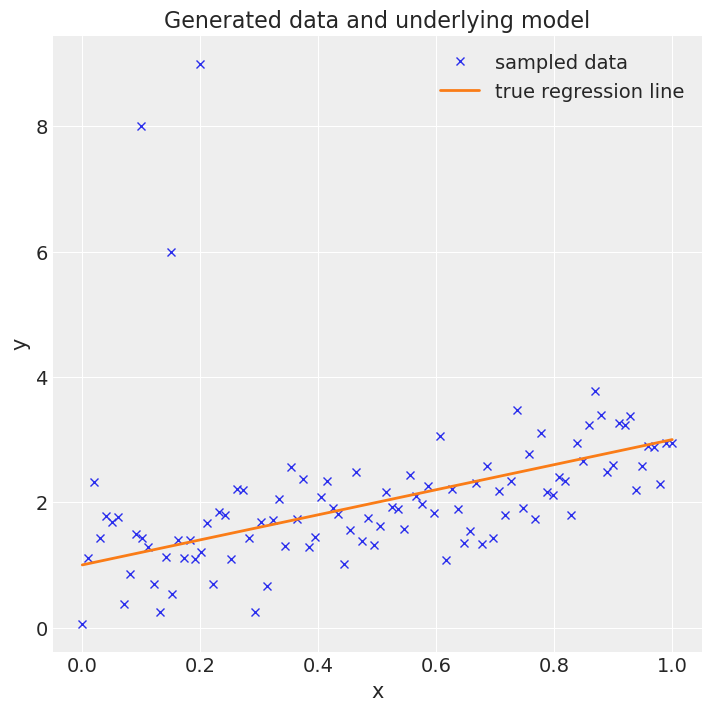
To highlight the problem, first fit a standard normally-distributed linear regression.
# Note, "gaussian" is the default argument for family. Added to be explicit.
gauss_model = bmb.Model("y ~ x", data, family="gaussian")
gauss_fitted = gauss_model.fit(idata_kwargs={"log_likelihood": True})
gauss_model.predict(gauss_fitted, kind="response")Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [sigma, Intercept, x]Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 1 seconds.az.summary(gauss_fitted, var_names="~mu")| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| sigma | 1.220 | 0.088 | 1.059 | 1.385 | 0.001 | 0.001 | 5472.0 | 2741.0 | 1.0 |
| Intercept | 1.509 | 0.237 | 1.066 | 1.947 | 0.003 | 0.004 | 6174.0 | 3141.0 | 1.0 |
| x | 1.153 | 0.414 | 0.424 | 1.946 | 0.005 | 0.007 | 6076.0 | 3355.0 | 1.0 |
Remember, the true intercept was 1, the true slope was 2. The recovered intercept is much higher, and the slope is much lower, so the influence of the outliers is apparent.
Visually, looking at the recovered regression line and posterior predictive HDI highlights the problem further.
fig, ax = plt.subplots(figsize=(7, 5))
# Plot data
ax.plot(x_out, y_out, "x", label="data")
# Plot recovered linear regression
x_range = np.linspace(min(x_out), max(x_out), 1000)
y_pred = (
gauss_fitted.posterior.x.mean().item() * x_range
+ gauss_fitted.posterior.Intercept.mean().item()
)
ax.plot(
x_range, y_pred, color="black", linestyle="--", label="Recovered regression line"
)
# Plot HDIs
for interval in [0.38, 0.68]:
az.plot_hdi(
x_out, gauss_fitted.posterior_predictive.y, hdi_prob=interval, color="firebrick"
)
# Plot true regression line
ax.plot(x, true_regression_line, label="True regression line", lw=2.0, color="black")
ax.legend(loc=0);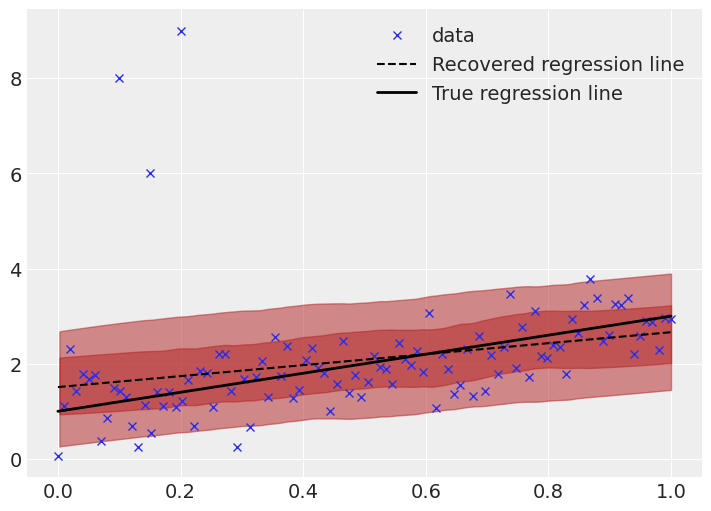
The recovered regression line, as well as the \(0.5\sigma\) and \(1\sigma\) bands are shown.
Clearly there is skew in the fit. At lower \(x\) values, the regression line is far higher than the true line. This is a result of the outliers, which cause the model to assume a higher value in that regime.
Additionally the uncertainty bands are too wide (remember, the \(1\sigma\) band ought to cover 68% of the data, while here it covers most of the points). Due to the small probability mass in the tails of a normal distribution, the outliers have a large effect, causing the uncertainty bands to be oversized.
Clearly, assuming the data are distributed normally is inducing problems here. Bayesian robust linear regression forgoes the normality assumption by instead using a Student T distribution to describe the distribution of the data. The Student T distribution has thicker tails, and by allocating more probability mass to the tails, outliers have a less strong effect.
Comparing the two distributions,
normal_data = np.random.normal(loc=0, scale=1, size=100_000)
t_data = np.random.standard_t(df=1, size=100_000)
bins = np.arange(-8, 8, 0.15)
plt.hist(normal_data, bins=bins, density=True, alpha=0.6, label="Normal")
plt.hist(t_data, bins=bins, density=True, alpha=0.6, label="Student T")
plt.xlabel("x")
plt.ylabel("Probability density")
plt.xlim(-8, 8)
plt.legend();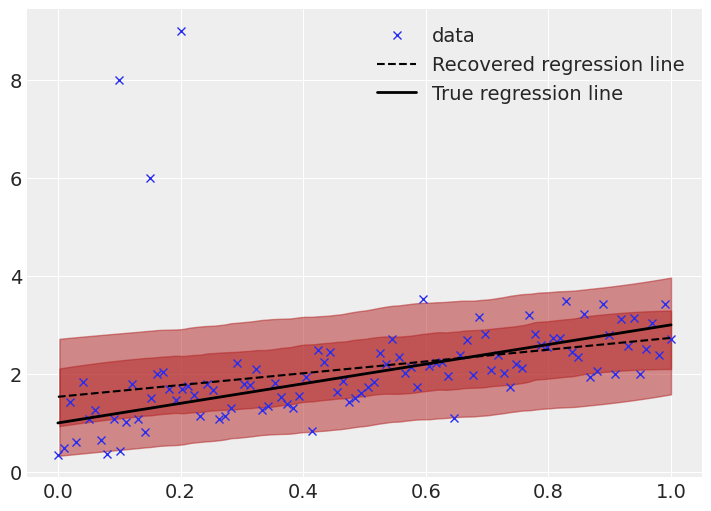
As we can see, the tails of the Student T are much larger, which means values far from the mean are more likely when compared to the normal distribution.
The T distribution is specified by a number of degrees of freedom (\(\nu\)). In numpy.random.standard_t this is the parameter df, in the pymc T distribution, it’s nu. It is constrained to real numbers greater than 0. As the degrees of freedom increase, the probability in the tails Student T distribution decrease. In the limit of \(\nu \rightarrow + \infty\), the Student T distribution is a normal distribution. Below, the T distribution is plotted for various \(\nu\).
bins = np.arange(-8, 8, 0.15)
for ndof in [0.1, 1, 10]:
t_data = np.random.standard_t(df=ndof, size=100_000)
plt.hist(t_data, bins=bins, density=True, label=f"$\\nu = {ndof}$", histtype="step")
plt.hist(normal_data, bins=bins, density=True, histtype="step", label="Normal")
plt.xlabel("x")
plt.ylabel("Probability density")
plt.xlim(-6, 6)
plt.legend();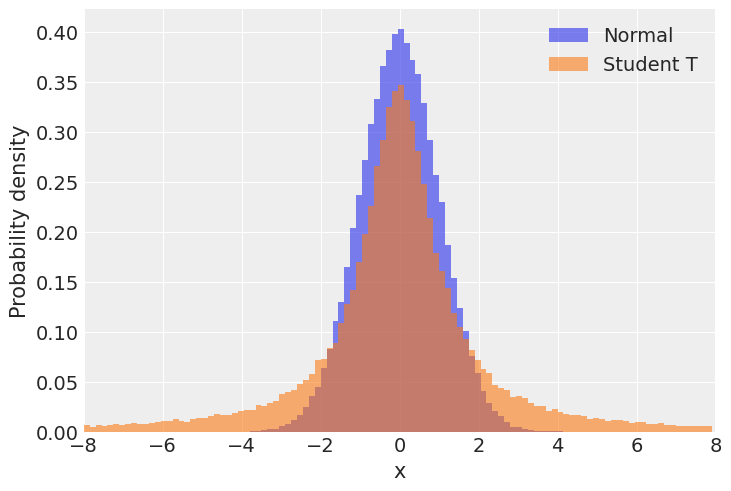
In Bambi, the way to specify a regression with Student T distributed data is by passing "t" to the family parameter of a Model.
t_model = bmb.Model("y ~ x", data, family="t")
t_fitted = t_model.fit(idata_kwargs={"log_likelihood": True})
t_model.predict(t_fitted, kind="response")Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [nu, sigma, Intercept, x]Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 1 seconds.az.summary(t_fitted, var_names="~mu")| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| nu | 2.690 | 0.678 | 1.496 | 3.894 | 0.012 | 0.012 | 3188.0 | 2797.0 | 1.0 |
| sigma | 0.468 | 0.055 | 0.374 | 0.580 | 0.001 | 0.001 | 3260.0 | 3116.0 | 1.0 |
| Intercept | 1.018 | 0.119 | 0.794 | 1.242 | 0.002 | 0.002 | 4053.0 | 3165.0 | 1.0 |
| x | 1.785 | 0.200 | 1.403 | 2.155 | 0.003 | 0.003 | 4234.0 | 3388.0 | 1.0 |
Note the new parameter in the model, y_nu. This is the aforementioned degrees of freedom. If this number were very high, we would expect it to be well described by a normal distribution. However, the HDI of this spans from 1.5 to 3.7, meaning that the tails are much heavier than a normal distribution. As a result of the heavier tails, y_sigma has also dropped precipitously from the normal model, meaning the oversized uncertainty bands from above have shrunk.
Comparing the extracted values of the two models,
def get_slope_intercept(mod):
return (mod.posterior.x.mean().item(), mod.posterior.Intercept.mean().item())
gauss_slope, gauss_int = get_slope_intercept(gauss_fitted)
t_slope, t_int = get_slope_intercept(t_fitted)
pd.DataFrame(
{
"Model": ["True", "Normal", "T"],
"Slope": [2, gauss_slope, t_slope],
"Intercept": [1, gauss_int, t_int],
}
).set_index("Model").T.round(decimals=2)| Model | True | Normal | T |
|---|---|---|---|
| Slope | 2.0 | 1.15 | 1.79 |
| Intercept | 1.0 | 1.51 | 1.02 |
Here we can see the mean recovered values of both the slope and intercept are far closer to the true values using the robust regression model compared to the normally distributed one.
Visually comparing the robust regression line,
fig, ax = plt.subplots(figsize=(7, 5))
# Plot data
ax.plot(x_out, y_out, "x", label="data")
# Plot recovered linear regression
x_range = np.linspace(min(x_out), max(x_out), 1000)
y_pred = (
t_fitted.posterior.x.mean().item() * x_range
+ t_fitted.posterior.Intercept.mean().item()
)
ax.plot(
x_range, y_pred, color="black", linestyle="--", label="Recovered regression line"
)
# Plot HDIs
for interval in [0.38, 0.68]:
az.plot_hdi(
x_out, t_fitted.posterior_predictive.y, hdi_prob=interval, color="firebrick"
)
# Plot true regression line
ax.plot(x, true_regression_line, label="True regression line", lw=2.0, color="black")
ax.legend(loc=0);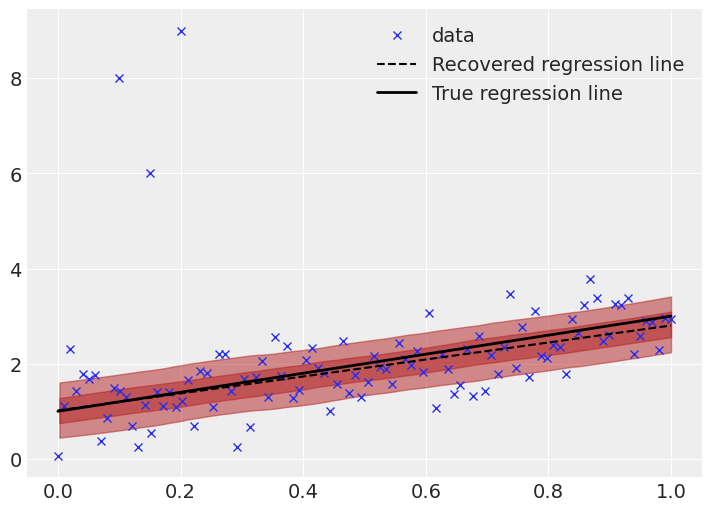
This is much better. The true and recovered regression lines are much closer, and the uncertainty bands are appropriate sized. The effect of the outliers is not entirely gone, the recovered line still slightly differs from the true line, but the effect is far smaller, which is a result of the Student T likelihood function ascribing a higher probability to outliers than the normal distribution. Additionally, this inference is based on sampling methods, so it is expected to have small differences (especially given a relatively small number of samples).
Last, another way to evaluate the models is to compare based on Leave-one-out Cross-validation (LOO), which provides an estimate of accuracy on out-of-sample predictions.
models = {
"gaussian": gauss_fitted,
"Student T": t_fitted
}
df_compare = az.compare(models)
df_compare/home/tomas/oss/bambinos/bambi/.pixi/envs/dev/lib/python3.13/site-packages/arviz/stats/stats.py:797: UserWarning: Estimated shape parameter of Pareto distribution is greater than 0.70 for one or more samples. You should consider using a more robust model, this is because importance sampling is less likely to work well if the marginal posterior and LOO posterior are very different. This is more likely to happen with a non-robust model and highly influential observations.
warnings.warn(| rank | elpd_loo | p_loo | elpd_diff | weight | se | dse | warning | scale | |
|---|---|---|---|---|---|---|---|---|---|
| Student T | 0 | -115.132811 | 5.146747 | 0.000000 | 1.0 | 14.413946 | 0.00000 | False | log |
| gaussian | 1 | -174.486283 | 13.466794 | 59.353472 | 0.0 | 28.033136 | 16.78544 | True | log |
az.plot_compare(df_compare, insample_dev=False);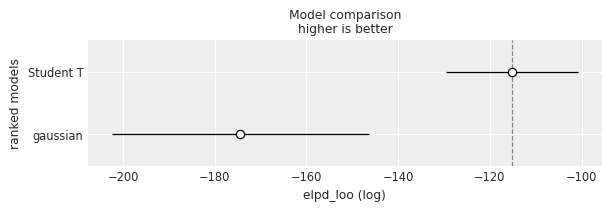
Here it is quite obvious that the Student T model is much better, due to having a clearly larger value of LOO.
%load_ext watermark
%watermark -n -u -v -iv -wLast updated: Sun Sep 28 2025
Python implementation: CPython
Python version : 3.13.7
IPython version : 9.4.0
bambi : 0.14.1.dev58+gb25742785.d20250928
arviz : 0.22.0
pandas : 2.3.2
matplotlib: 3.10.6
numpy : 2.3.3
Watermark: 2.5.0