import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import scipy
from lifelines import KaplanMeierFitter
import bambi as bmbSurvival Models
Survival models, also known as time-to-event models, are specialized statistical methods designed to analyze the time until the occurrence of an event of interest. In this notebook, a review of survival analysis (using non-parametric and parametric methods) and censored data is provided, followed by a survival model implementation in Bambi.
Survival and censoring times
Sometimes the right way to model discrete, countable events is to model not the counts themselves but rather the time between events. This gives us information regarding the rate of an event. Survival models are models for countable things, but the outcomes we want to predict are durations. Durations are continuous deviations from some point of reference (so they are all positive values).
The tricky part with survival models is not the probability distribution assigned to the durations, but dealing with censoring. Censoring occurs when the event of interest does not occur in the window of observation. In a simple scenario, this can happen because the observation period ends before the event occurred. Censored individuals (or units) can not just be dropped from the sample. As an example, we use Richard McElreath’s cat adoption example from chapter 11.4 of Statistical Rethinking: Imagine a cohort of 100 cats who start waiting for adoption at the same time. After one month, half of them have been adopted. Now what is the rate of adoption? You can’t compute it using only the cats who have been adopted. You need to also account for the cats who haven’t yet been adopted. The cats who haven’t been adopted yet, but eventually will be adopted, clearly have longer waiting times than the cats who have already been adopted. So the average rate among those who are already adopted is biased upwards—it is confounded by conditioning on adoption.
Including censored observations requires a new type of model. The key idea is that the same distribution assumption for the outcome tells us both the probability of any observed duration that end in the event as well as the probability that we would wait the observed duration without seeing the event. For each unit, we assume there is a true survival time \(T\) as well as a true censoring time \(C\). The survival time represents the time at which the event of interest occurs. The censoring time is the time at which censoring occurs. We observe either: the survival, or the censoring time:
\[Y = \text{min}(T, C)\]
If the event occurs, then we observe the survival time, else we observe the censoring time. In order to analyze survival data, we first need to understand the two types of censoring: left and right censoring, and how to estimate the survival function.
Left and right censoring
There are two main “types” of censoring: right and left. Right censoring occurs when \(T \ge Y\), i.e. the true event time \(T\) is at least as large as the observed time \(Y\). This is a consequence of \(Y = \text{min}(T, C)\). Right censoring derives its name from the notion that time is typically read and displayed from left to right. Left sensoring occurs when the true event time \(T\) is less than or equal to the observed time \(Y\). An example of left censoring could be in a study of pregnancy duration. Suppose that patients are surveyed 250 days (8.2 months) after conception. Some patients may have already had their babies. For these patients, pregnancy duration is less than 250 days.
Estimating the survival function
Survival analysis is concerned with estimating the survival function \(S(t)\)
\[S(t) = Pr(T > t) = 1 - F(t)\]
which is a decreasing function that quantifies the probability of surviving past time \(t\). Alternatively, \(S(t)\) can be expressed as one minus the cumulative distribution function (CDF) \(F\) of the event time \(T\)—referred to as the complementary cumulative distribution function (CCDF). The focus on the survival function is important because for censored observations, we only know that the time-to-event exceeds the observed time \(Y\).
Here, continuing with the cat adoption example, we consider the task of estimating the survival function for cat adoptions. To estimate \(S(30) = Pr(T > 30)\), the probability that a cat is not adopted after 30 days, it is tempting to compute the proportion of cats who were adopted before 30 days and subtract this from 1. However, this would be incorrect because it ignores the cats who were not adopted before 30 days but who will be adopted later—these cats clearly have longer adoption rates. Thus, if we continued with the naive approach, the average rate of adoption would be biased upwards—it is confounded by conditioning on adoption.
However, it is possible to overcome this challenge by using the Kaplan-Meier estimator. The Kaplan-Meier estimator is a non-parametric estimator of the survival function that accounts for censoring. Let \(d_1 < d_2 < . . . < d_K\) denote the \(K\) unique adoption times among the non-censored cats, and \(q_k\) denote the number of cats adopted at time \(d_k\). For \(k = 1,...,K\), let \(r_k\) denote the number of cats not adopted at time \(d_k\). By the law of total probability
\[Pr(T > d_k) = Pr(T > d_k | T > d_{k-1}) Pr(T > d_{k-1}) + Pr(T > d_k | T \leq d_{k-1}) Pr(T \leq d_{k-1})\]
The fact that \(d_{k-1} < d_k\) implies that \(Pr(T > d_k | T \leq d_{k-1}) = 0\) (as it is impossible for a cat to be adopted past time \(d_k\) if the cat was adopted before time \(d_{k-1}\)). Thus, if we simplify the above equation and plug into the survival function, we obtain
\[S(d_k) = Pr(T > d_k | T > d_{k-1})S(d_{k-1})\]
Now we must estimate the terms on the right-hand side. It is common to use the following estimator
\[\hat{Pr}(T > d_j | T > d_{j-1}) = \frac{r_j - q_j}{r_j}\]
which leads us to the Kaplan-Meier estimator of the survival function
\[\hat{S}(d_k) = \prod_{j=1}^k \frac{r_j - q_j}{r_j}\]
where \(\hat{S}(d_k)\) represents the estimated survival probability up to time \(d_k\). The product is taken over all time points up to \(k\), where an event occurred. The variables \(r_j\) and \(q_j\) denote the number of subjects at risk and the number of events at time \(d_j\), respectively. The term \(\frac{r_j - q_j}{r_j}\) is the conditional probability of surviving the \(j\)-th time point given that an individual has survived just before \(d_j\). Specifically, \(r_j - q_j\) are the number of individuals who survived just before \(d_j\) and \(r_j\) is the number of individuals who survived just after \(d_j\), and \(r_j\) are those who were at risk \(d_j\).
Cat adoption survival function
Below we use the KaplanMeierFitter class of the lifelines package to compute and visualize the survival curve for cat adoptions from an animal shelter in Austin, Texas beginning October 1st, 2013 until May 30th, 2018 (the last day the shelter rescued a cat). The dataset comes from the City of Austin Open Data Portal and contains columns such as animal name, date of birth, species, and many more. However, for the purpose of this notebook we are interested in the following columns: - days_to_event - number of days until the cat was adopted (date_in - date_out) - out_event - the reason for the cat leaving this particular shelter, e.g. adopted or transfered. - color - the color of the cat, e.g. white, blue, brown tabby, black.
url = "https://raw.githubusercontent.com/rmcelreath/rethinking/master/data/AustinCats.csv"
cats_df = pd.read_csv(url, sep=";")plt.figure(figsize=(7, 3))
plt.hist(cats_df["days_to_event"], bins=250, label="Uncensored data")
plt.xlim(0, 186) # limit to 6 months for visibility
plt.title("Days Until Adoption")
plt.ylabel("Count")
plt.xlabel("Days")
plt.legend();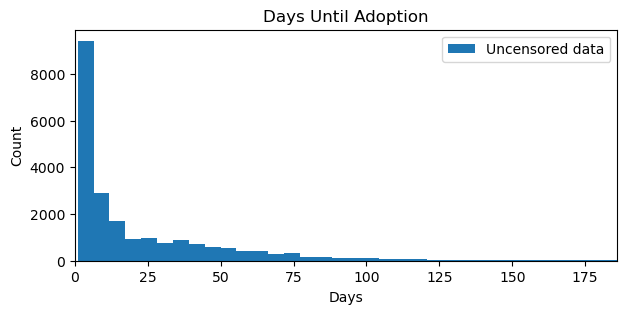
The distribution of days until adoption exhibits a long tail with most cats (if we observe the adopt event) being adopted within the first month of inception. Note that the plot has been truncated to six months for better visibility. Below, we estimate the survival function using the KaplanMeierFitter class from the lifelines package.
km = KaplanMeierFitter()
km_adoptions = km.fit(
cats_df["days_to_event"],
cats_df["out_event"].apply(lambda x: 1 if x == "Adoption" else 0)
)fig, ax = plt.subplots(figsize=(7, 3))
km_adoptions.plot(label="Kaplan-Meier Estimator", ax=ax)
ax.set_ylabel("Probability of Adoption")
ax.set_xlabel("Days")
ax.set_xlim(0, 365)
ax.grid(True)
ax.set_title("Cat Adoption Survival Curve");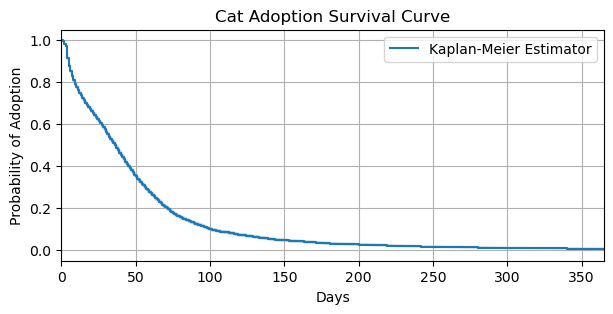
The Kaplan-Meier estimator shows that by 100 days, the probability of a cat not being adopted is about \(0.15\) percent. After 100 days, the probability of cat not being adopted decreases, albeit at a much slower rate. Thus, if a cat hasn’t been adopted by the 100th day, it is more likely the cat will continue to wait for adoption. In the next section, we discuss pm.Censored, a PyMC distrbution that allows us to model censored data.
The pm.Censored distribution
The censored distribution from PyMC allows us to make use of a sequential construction, similar to the Kaplan-Meier estimator outlined above, to model censored data. To understand the pm.Censored distribution, let’s reason how a distribution may be used to model censored data. For observed adoptions, the probability of observed waiting time can be distributed according to an exponential with some rate \(\lambda\) \[D_i \sim \text{Exponential}(\lambda_i)\] or \[f(D_i | \lambda_i) = \lambda_i \text{exp}(-\lambda_i D_i)\] It’s the censored cats that are tricky. If something else happened before a cat could be adopted, or it simply hasn’t been adopted yet, then we need the probability of not being adopted, conditional on the observation time so far. One way to motivate this is to image a cohort of 100 cats, all joining the shelter on the same day. - If half have been adopted after 30 days, then the probability of waiting 30 days and still not being adopted is 0.5. - If after 60 days, only 25 remain, then the probability of waiting 60 days and not yet being adopted is 0.25.
Thus, any given rate of adoption implies a proportion of the cohort of 100 cats that will remain after any given number of days. This probability comes from the cumulative probability distribution. A cumulative distribution gives the proportion of cats adopted before or at a certain number of days. So \(1 - \text{CDF}\), which is the CCDF, gives the probability a cat is not adopted by the same number of days. Remember from the Estimating the survival function section, this is equivalent to the survival function. If the exponential distribution is used, the CDF is
\[F(D_i | \lambda_i) = 1 - \text{exp}(-\lambda_i D_i)\]
where the complement is (here we use \(S\) to denote the equivalence of the survival function and CCDF)
\[S(D_i|\lambda) = \text{exp}(-\lambda_i D_i)\]
Which is what we need in our model since it is the probability of waiting \(D_i\) days without being adopted yet. The pm.Censored from PyMC offers a convenient way to model censored data and the probability density function (PDF) is defined as
where lower is left-censored and upper is right-censored. Our cat adoption dataset is right-censored. Therefore, lower can be None, and upper is the observed times when an event occurs. The pm.Censored uses the CCDF to answer the question we are interested in: what is the probability of not being adopted yet, given the observation time so far?
Implementation in Bambi
To understand how this is used, let’s use Bambi to recover the parameters of the censored distribution with no predictors. Before the model is fit, days_to_event is scaled to represent months as the raw values contain very large values. This scaling ensures a smoother sampling process.
Additionally, modeling censored data in Bambi requires a new formula syntax censored(time, event) on the response term. censored indicates we want to model censored data and gets parsed where time and event are passed into a Bambi transformation function censored. This function takes two arguments: the first being the observed value \(Y\) (in this example time), and the second being the type of censoring of the event. In Bambi, it is possible to have left, none, right, and interval censoring. event needs to be encoded as one of the censoring types. In our cat adoption example, we will encode the adoption event as right.
Lastly, the exponential distribution is used to model the cat adoption rate parameter. But why not enter censored as the likelihood like we normally do in Bambi? The pm.Censored is indeed eventually used as the likelihood. However, there also needs to be a distribution that models the rate parameter. In this example it is the exponential distribution. This distribution is then used as input into the pm.Censored distribution. For more information on how to use the pm.Censored distribution, see the following PyMC documentation: Bayesian regression models with truncated and censored data and Censored data models.
cats = cats_df.copy()
cats["adopt"] = np.where(cats["out_event"] == "Adoption", "right", "none")
cats["color_id"] = np.where(cats["color"] == "Black", 1, 0)
cats = cats[["days_to_event", "adopt", "color_id"]]model_1 = bmb.Model(
"censored(days_to_event / 31, adopt) ~ 1",
data=cats,
family="exponential",
link="log"
)
model_1.build()
model_1.graph()
idata_1 = model_1.fit(tune=500, draws=500, random_seed=42, chains=4)Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [Intercept]Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 4 seconds.az.plot_trace(idata_1);
summary = az.summary(idata_1)
summary| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| Intercept | 0.502 | 0.01 | 0.485 | 0.521 | 0.0 | 0.0 | 985.0 | 1570.0 | 1.0 |
Interpreting the intercept (the cat adoption rate parameter) alone is of not much value. Therefore, let’s use the survival function to compute the probability of not being adopted after a range of months, given the learned rate parameter \(\lambda\). We could dervive the survival function and pass the intercept parameter to it, but SciPy already implements it as scipy.stats.expon.sf, so we will just use this implementation.
Cat adoption plots
The plot below shows the estimated survival function and CCDF for cat adoptions. First, we compute the \(0.95\) credible interval (CI) and median value for the intercept. Then, since a log-link was used, the values are exponentiated.
lambda_preds = np.quantile(
idata_1["posterior"]["Intercept"],
[0.025, 0.5, 0.975]
)
lambda_lower = 1 / np.exp(lambda_preds[0])
lambda_median = 1 / np.exp(lambda_preds[1])
lambda_upper = 1 / np.exp(lambda_preds[2])t = np.linspace(0, max(cats["days_to_event"] / 31), 100)
S0 = scipy.stats.expon.sf
cdf = scipy.stats.expon.cdf
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(10, 3), sharey=True)
ax[0].plot(t, S0(lambda_median * t))
ax[0].fill_between(t, S0(lambda_lower * t), S0(lambda_upper * t), alpha=0.25)
ax[0].grid(True)
ax[0].set_xlim(0, 12)
ax[0].set_xlabel("Months")
ax[0].set_ylabel("Probability")
ax[0].set_title("Probability Not Being Adopted by Time $d_k$")
ax[1].plot(t, cdf(lambda_median * t))
ax[1].fill_between(t, cdf(lambda_lower * t), cdf(lambda_upper * t), alpha=0.25)
ax[1].grid(True)
ax[1].vlines(1, 1, 1, linestyles="dashed")
ax[1].set_xlabel("Months")
ax[1].set_ylabel("Probability")
ax[1].set_title("Probability of Being Adopted by Time $d_k$");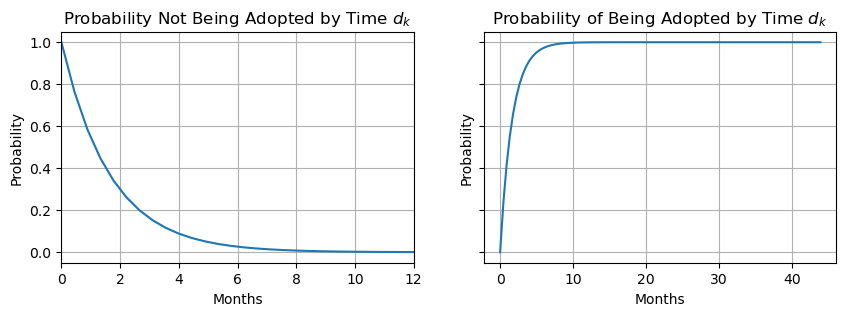
Analyzing the CCDF (the left plot), the probability of a cat waiting one month without being adopted is about \(0.60\), whereas the probability of a cat being adopted by the first month is about \(0.40\). Analyzing the CDF (right plot), the majority of cats, about \(0.97\), are adopted by the sixth month. Now that we have an intuition on how pm.Censored is used for modeling censored data, in the next section, we will discuss how to model censored data with predictors.
Regression models with a survival response
It is often the case that we would like to understand how various predictors are associated with the survival function. For example, we may want to know if the survival function for cats of different colors or species is different. As outlined above, we cannot simply run a regression on the observed times \(Y\) given some predictors \(X\). What we are actually interested in is predicting the survival time \(T\) given the predictors \(X\). To achieve this, we first need to understand the Hazard function and the Cox proportional hazards model.
The hazard function
In survival analysis, it is often more convenient to express the survival function in terms of the hazards rate, which is closely related to the survival function \(S(t)\), and is the instantaneous rate of an event occuring at time \(t\) given that the event has not yet occured.
\[\begin{split}\begin{align*} \lambda(t) & = \lim_{\Delta t \to 0} \frac{P(t < T < t + \Delta t\ |\ T > t) / \Delta t}{Pr(T > t)} \\ & = \lim_{{\Delta t \to 0}} \frac{Pr(t < T \leq t + \Delta t) / \Delta t}{Pr(T > t)} \\ & = \frac{f(t)}{S(t)} \end{align*}\end{split}\]where
\[f(t) = \lim_{{\Delta t \to 0}} \frac{Pr(t < T \leq t + \Delta t)}{\Delta t}\]
where \(T\) is the (unobserved) survival time and \(f(t)\) is the PDF associated with \(T\). The relationship between the hazard function and the survival function can be described in terms of the likelihood \(L\)
\[\begin{equation} L_i = \begin{cases} f(y_i) & \text{if the } i\text{th observation is not censored} \\ S(y_i) & \text{if the } i\text{th observation is censored} \end{cases} \end{equation}\]
If \(Y = y_i\) and the \(i\text{th}\) observation is not censored, then the likelihood is the probability of the event in a tiny interval around time \(y_i\). If the \(i\text{th}\) observation is censored, then the likelihood is the probability of surviving at least until time \(y_i\). We have now seen two ways to model the survival times: (1) a non-parametric estimator such as Kaplan-Meier, and (2) a parametric model using the PDF \(f(t)\) to estimate the hazard rate. However, what we would really like to do is to model the survival time as a function of the predictors. Thus, instead of working with the PDF \(f(t)\), we work directly with the hazard function to model the survival time as a function of predictors.
The Cox proportional hazards model
Above, we developed a model with no predictors to recover the parameters of the cat adoption rate, and used this as input into the pm.Censored distribution. Since we would now like to add predictor(s), we need to reformulate our modeling task into a risk regression model as it allows us to model the hazard rate as a function of our predictors. Specifically, the Cox proportional hazards model. With predictors \(x_j\) and regression coefficients \(\beta\), the hazard rate is modeled as
\[\lambda(t|x_i) = \lambda_0(t)\text{exp}(\sum_{j=1}^p x_{ij}\beta_j)\]
where \(\lambda_{0}t\) is the baseline hazard rate independent of the predictors. This baseline hazard rate is unspecified (or unidentified) and means that we allow the instantaneous probability of an event at time \(t\), given that a subject has survived at least until time \(t\), to take any form. Practically speaking, this means that the hazard function is very flexible and can model a wide range of relationships between the covariates and survival time. One can interpret the Cox proportional hazards model as a one-unit increase in \(x_{ij}\) corresponds to an increase in \(\lambda(t, x_i)\) by a factor of \(\text{exp}(\beta_j)\). In the next section, it is discussed how to develop a regression model with survival responses and predictors.
Implementation in Bambi
Adding predictors to model the hazard rate as a function of our predictors is trivial in Bambi. We simply continue to use the formula syntax. In the backend, the rate is modeled as a function of the specified predictors in the Bambi model. For example, if in the Bambi model, we specified censored(y, event) ~ 1 + x with an exponential likelihood, then the latent rate \(\lambda\) is modeled as an exponential distribution according to
\[\alpha \sim \mathcal{N}(0, 1)\] \[\beta \sim \mathcal{N}(0, 1)\] \[\mu = \text{exp}(\alpha + \beta X)\] \[\lambda = 1 / \mu\] \[Y \sim \text{Exponential}(\lambda)\]
where \(Y\) is then passed to the dist argument of the pm.Censored distribution.
Cat adoption rates by color
However, thanks to Bambi’s formula syntax, we can just include the predictors of interest. Below, color_id is added to model the survival probability of black and other colored cats.
cat_model = bmb.Model(
"censored(days_to_event / 31, adopt) ~ 0 + color_id",
data=cats,
center_predictors=False,
priors={"color_id": bmb.Prior("Normal", mu=0, sigma=1)},
categorical=["color_id"],
family="exponential",
link="log"
)
cat_model.build()
cat_model.graph()
cat_model Formula: censored(days_to_event / 31, adopt) ~ 0 + color_id
Family: exponential
Link: mu = log
Observations: 22356
Priors:
target = mu
Common-level effects
color_id ~ Normal(mu: 0.0, sigma: 1.0)idata = cat_model.fit(tune=500, draws=500, random_seed=42, chains=4)Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [color_id]Sampling 4 chains for 500 tune and 500 draw iterations (2_000 + 2_000 draws total) took 6 seconds.az.summary(idata)| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| color_id[0] | 0.490 | 0.011 | 0.469 | 0.509 | 0.000 | 0.000 | 2080.0 | 1568.0 | 1.0 |
| color_id[1] | 0.568 | 0.025 | 0.521 | 0.614 | 0.001 | 0.001 | 2370.0 | 1579.0 | 1.0 |
The summary output informs us that, on average, the rate parameter for other cats color_id[0] is lower than the rate for black cats color_id[1]. As performed above, let’s plot the survival curves and CDFs for black and other colored cats to get a better understanding of the rate parameters.
Cat adoption plots
In the inference data, we have posterior draws for color_id (with corresponding coordinates for other and black cats) where the values represent the sampled rates. However, it is also possible to obtain \(Y\), in this example, months to event (as our data has been scaled) by calling model.predict() on the observed or new data. This will add a new data variable mu to the posterior group of the inference data.
new_data = pd.DataFrame({"color_id": [0, 1]})
cat_model.predict(idata, data=new_data, kind="response")other_cats = (
idata["posterior"]["mu"]
.sel({"__obs__": 0})
.values
.flatten()
)
other_cats_preds = np.quantile(other_cats, [0.025, 0.5, 0.975])
black_cats = (
idata["posterior"]["mu"]
.sel({"__obs__": 1})
.values.
flatten()
)
black_cats_preds = np.quantile(black_cats, [0.025, 0.5, 0.975])
lambdas = {
"Other cats": 1 / other_cats_preds,
"Black cats": 1 / black_cats_preds
}fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(10, 3), sharey=True)
for key, value in lambdas.items():
lower, median, upper = value
ax[0].plot(t, S0(median * t), label=f"{key}")
ax[0].fill_between(t, S0(lower * t), S0(upper * t), alpha=0.25)
ax[0].grid(True)
ax[0].set_xlim(0, 10)
ax[0].legend()
ax[0].set_title("Probability Not Being Adopted by Time $d_k$")
for key, value in lambdas.items():
lower, median, upper = value
ax[1].plot(t, cdf(median * t), label=f"{key}")
ax[1].fill_between(t, cdf(lower * t), cdf(upper * t), alpha=0.25)
ax[1].grid(True)
ax[1].set_xlim(0, 10)
ax[1].legend()
ax[1].set_title("Probability of Being Adopted by Time $d_k$");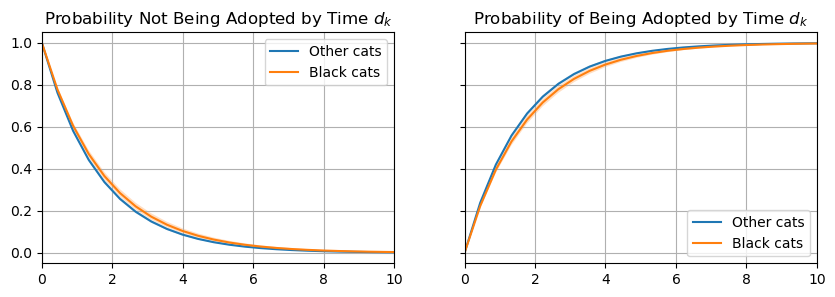
Analyzing the CCDF (left plot), we can see that black cats have a slightly higher probability of not being adopted throughout the whole range of \(k\). Furthermore, analyzing the CDF (right plot), we can see it also takes a longer time for the majority of black cats to be adopted compared to other colored cats. Below, we plot the distribution of days until adoption for the two groups.
plt.figure(figsize=(7, 3))
plt.hist(
other_cats * 31,
bins=50,
density=True,
label="Other cats"
)
plt.hist(
black_cats * 31,
bins=50,
density=True,
label="Black cats"
)
plt.legend()
plt.xlabel("Days")
plt.ylabel("Density")
plt.title("Distribution of Adoption Times");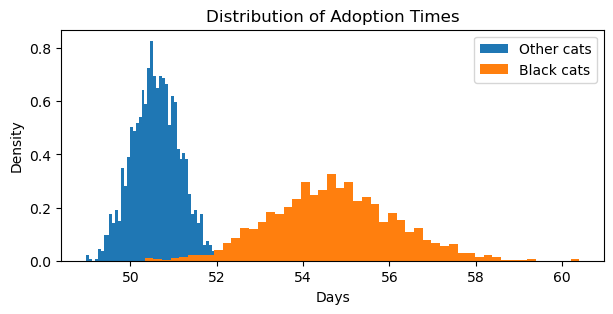
Scaling adoption times back to days (multiplying by 31), we can see that black cats have longer and a wider range of time until adoptions (about 55 days) than cats that are not black (about 51 days).
Summary
In this notebook, we introduced censored data, left and right censoring, and why such data lends itself to specialized statistical methods and models. First, the non-parametric Kaplan-Meier estimator to estimate the survival curve of censored data was introduced. Subsequently, motivated by modeling the survival function as a function of predictors, the hazards rate and Cox proportional hazards model was introduced. Modeling censored data in Bambi requires defining the response as censored(y, event) where event is left or right censoring. To add predictors to the model, simply include them in the formula. Bambi leverages the pm.Censored distribution from PyMC as the likelihood for censored data.
%load_ext watermark
%watermark -n -u -v -iv -wLast updated: Tue Dec 16 2025
Python implementation: CPython
Python version : 3.13.9
IPython version : 9.6.0
arviz : 0.22.0
lifelines : 0.30.0
numpy : 2.3.3
scipy : 1.16.2
pandas : 2.3.3
matplotlib: 3.10.7
bambi : 0.15.1.dev47+g707bbd9e5.d20251216
Watermark: 2.5.0