import arviz as az
import bambi as bmb
import matplotlib.pyplot as plt
az.style.use("arviz-darkgrid")Wald and Gamma Regression (Australian insurance claims 2004-2005)
Load and examine Vehicle insurance data
In this notebook we use a data set consisting of 67856 insurance policies and 4624 (6.8%) claims in Australia between 2004 and 2005. The original source of this dataset is the book Generalized Linear Models for Insurance Data by Piet de Jong and Gillian Z. Heller.
data = bmb.load_data("carclaims")
data.head()| veh_value | exposure | clm | numclaims | claimcst0 | veh_body | veh_age | gender | area | agecat | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.06 | 0.303901 | 0 | 0 | 0.0 | HBACK | 3 | F | C | 2 |
| 1 | 1.03 | 0.648871 | 0 | 0 | 0.0 | HBACK | 2 | F | A | 4 |
| 2 | 3.26 | 0.569473 | 0 | 0 | 0.0 | UTE | 2 | F | E | 2 |
| 3 | 4.14 | 0.317591 | 0 | 0 | 0.0 | STNWG | 2 | F | D | 2 |
| 4 | 0.72 | 0.648871 | 0 | 0 | 0.0 | HBACK | 4 | F | C | 2 |
Let’s see the meaning of the variables before creating any plot or fitting any model.
- veh_value: Vehicle value, ranges from \$0 to \$350,000.
- exposure: Proportion of the year where the policy was exposed. In practice each policy is not exposed for the full year. Some policies come into force partly into the year while others are canceled before the year’s end.
- clm: Claim occurrence. 0 (no), 1 (yes).
- numclaims: Number of claims.
- claimcst0: Claim amount. 0 if no claim. Ranges from \$200 to \$55922.
- veh_body: Vehicle body type. Can be one of bus, convertible, coupe, hatchback, hardtop, motorized caravan/combi, minibus, panel van, roadster, sedan, station wagon, truck, and utility.
- veh_age: Vehicle age. 1 (new), 2, 3, and 4.
- gender: Gender of the driver. M (Male) and F (Female).
- area: Driver’s area of residence. Can be one of A, B, C, D, E, and F.
- agecat: Driver’s age category. 1 (youngest), 2, 3, 4, 5, and 6.
The variable of interest is the claim amount, given by "claimcst0". We keep the records where there is a claim, so claim amount is greater than 0.
data = data[data["claimcst0"] > 0]For clarity, we only show those claims amounts below \$15,000, since there are only 65 records above that threshold.
data[data["claimcst0"] > 15000].shape[0]65plt.hist(data[data["claimcst0"] <= 15000]["claimcst0"], bins=30)
plt.title("Distribution of claim amount")
plt.xlabel("Claim amount ($)");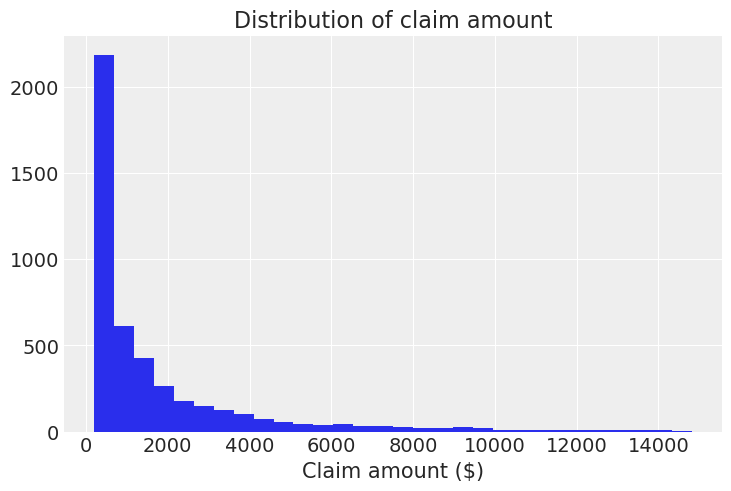
And this is when you say: “Oh, there really are ugly right-skewed distributions out there!”. Well, yes, we’ve all been there :)
In this case we are going to fit GLMs with a right-skewed distribution for the random component. This time we will be using Wald and Gamma distributions. One of their differences is that the variance is proportional to the cubic mean in the case of the Wald distribution, and proportional to the squared mean in the case of the Gamma distribution.
Wald family
The Wald family (a.k.a inverse Gaussian model) states that
\[ \begin{array}{cc} y_i \sim \text{Wald}(\mu_i, \lambda) & g(\mu_i) = \mathbf{x}_i^T\beta \end{array} \]
where the pdf of a Wald distribution is given by
\[ f(x|\mu, \lambda) = \left(\frac{\lambda}{2\pi}\right)^{1/2}x^{-3/2}\exp\left\{ -\frac{\lambda}{2x} \left(\frac{x - \mu}{\mu} \right)^2 \right\} \]
for \(x > 0\), mean \(\mu > 0\) and \(\lambda > 0\) is the shape parameter. The variance is given by \(\sigma^2 = \mu^3/\lambda\). The canonical link is \(g(\mu_i) = \mu_i^{-2}\), but \(g(\mu_i) = \log(\mu_i)\) is usually preferred, and it is what we use here.
Gamma family
The default parametrization of the Gamma density function is
\[ \displaystyle f(x | \alpha, \beta) = \frac{\beta^\alpha x^{\alpha -1} e^{-\beta x}}{\Gamma(\alpha)} \]
where \(x > 0\), and \(\alpha > 0\) and \(\beta > 0\) are the shape and rate parameters, respectively.
But GLMs model the mean of the function, so we need to use an alternative parametrization where
\[ \begin{array}{ccc} \displaystyle \mu = \frac{\alpha}{\beta} & \text{and} & \displaystyle \sigma^2 = \frac{\alpha}{\beta^2} \end{array} \]
and thus we have
\[ \begin{array}{cccc} y_i \sim \text{Gamma}(\mu_i, \sigma_i), & g(\mu_i) = \mathbf{x}_i^T\beta, & \text{and} & \sigma_i = \mu_i^2/\alpha \end{array} \]
where \(\alpha\) is the shape parameter in the original parametrization of the gamma pdf. The canonical link is \(g(\mu_i) = \mu_i^{-1}\), but here we use \(g(\mu_i) = \log(\mu_i)\) again.
Model fit
In this example we are going to use the binned age, the gender, and the area of residence to predict the amount of the claim, conditional on the existence of the claim because we are only working with observations where there is a claim.
"agecat" is interpreted as a numeric variable in our data frame, but we know it is categorical, and we wouldn’t be happy if our model takes it as if it was numeric, would we?
We have two alternatives to tell Bambi that this numeric variable must be treated as categorical. The first one is to wrap the name of the variable with C(), and the other is to pass the same name to the categorical argument when we create the model. We are going to use the first approach with the Wald family and the second with the Gamma.
The C() notation is taken from Patsy and is encouraged when you want to explicitly pass the order of the levels of the variables. If you are happy with the default order, better pass the name to categorical so tables and plots have prettier labels :)
Wald
model_wald = bmb.Model("claimcst0 ~ C(agecat) + gender + area", data, family = "wald", link = "log")
fitted_wald = model_wald.fit(tune=2000, target_accept=0.9, idata_kwargs={"log_likelihood": True})Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [lam, Intercept, C(agecat), gender, area]Sampling 4 chains for 2_000 tune and 1_000 draw iterations (8_000 + 4_000 draws total) took 8 seconds.az.plot_trace(fitted_wald);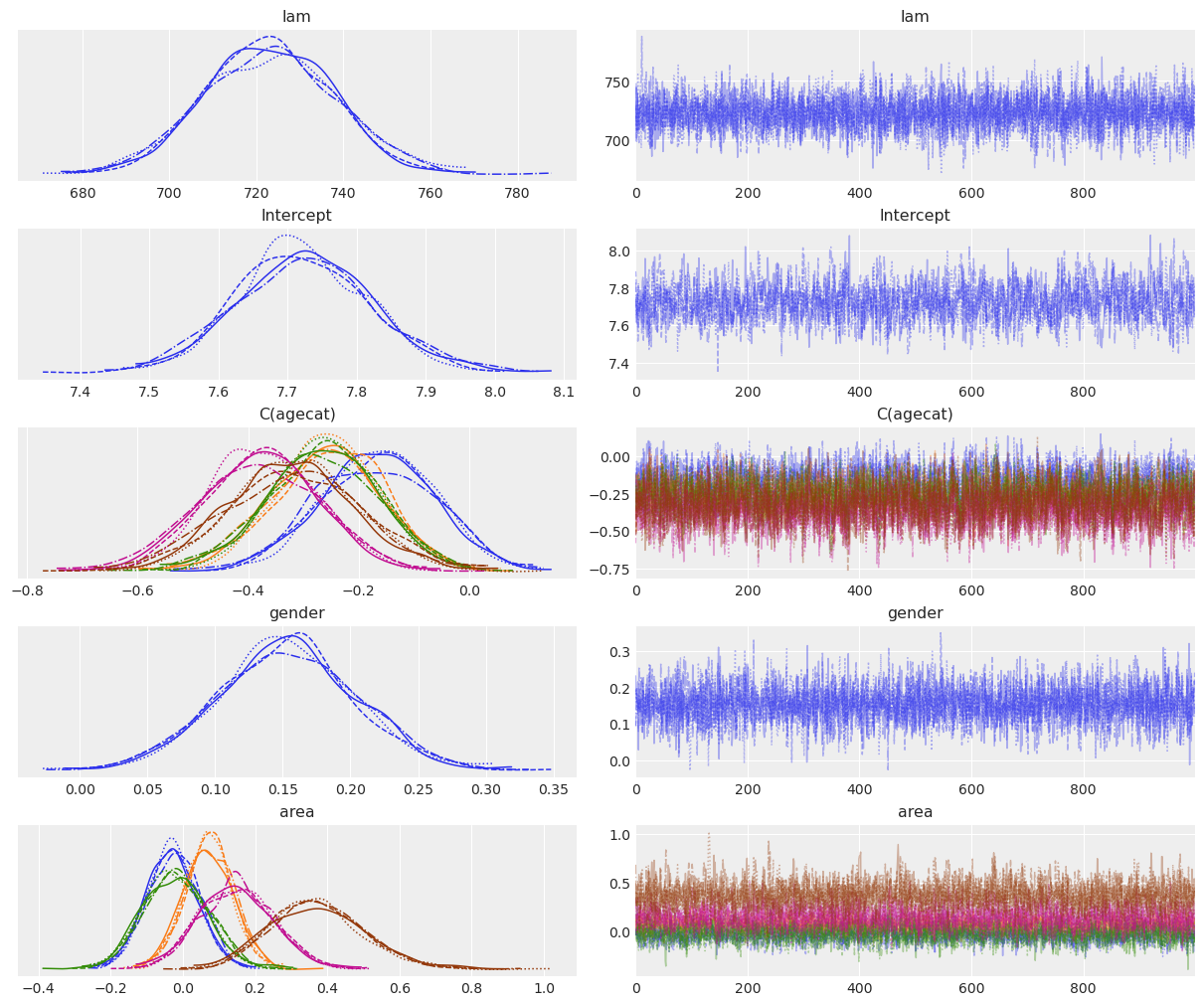
az.summary(fitted_wald)| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| lam | 722.968 | 14.905 | 696.637 | 752.641 | 0.216 | 0.251 | 4774.0 | 3157.0 | 1.0 |
| Intercept | 7.724 | 0.096 | 7.537 | 7.901 | 0.002 | 0.002 | 1540.0 | 1997.0 | 1.0 |
| C(agecat)[2] | -0.166 | 0.104 | -0.354 | 0.031 | 0.003 | 0.002 | 1663.0 | 1897.0 | 1.0 |
| C(agecat)[3] | -0.258 | 0.099 | -0.443 | -0.075 | 0.002 | 0.002 | 1628.0 | 1835.0 | 1.0 |
| C(agecat)[4] | -0.265 | 0.099 | -0.462 | -0.084 | 0.002 | 0.002 | 1631.0 | 2030.0 | 1.0 |
| C(agecat)[5] | -0.378 | 0.106 | -0.567 | -0.176 | 0.003 | 0.002 | 1775.0 | 2328.0 | 1.0 |
| C(agecat)[6] | -0.318 | 0.119 | -0.543 | -0.093 | 0.003 | 0.002 | 1918.0 | 2524.0 | 1.0 |
| gender[M] | 0.153 | 0.051 | 0.051 | 0.243 | 0.001 | 0.001 | 4755.0 | 3093.0 | 1.0 |
| area[B] | -0.029 | 0.072 | -0.162 | 0.107 | 0.001 | 0.001 | 2535.0 | 2680.0 | 1.0 |
| area[C] | 0.072 | 0.068 | -0.053 | 0.204 | 0.001 | 0.001 | 2732.0 | 2642.0 | 1.0 |
| area[D] | -0.021 | 0.090 | -0.190 | 0.137 | 0.002 | 0.001 | 3084.0 | 2932.0 | 1.0 |
| area[E] | 0.149 | 0.103 | -0.045 | 0.335 | 0.002 | 0.001 | 3172.0 | 3188.0 | 1.0 |
| area[F] | 0.372 | 0.131 | 0.133 | 0.616 | 0.002 | 0.002 | 3135.0 | 2384.0 | 1.0 |
If we look at the agecat variable, we can see the log mean of the claim amount tends to decrease when the age of the person increases, with the exception of the last category where we can see a slight increase in the mean of the coefficient (-0.307 vs -0.365 of the previous category). However, these differences only represent a slight tendency because of the large overlap between the marginal posteriors for these coefficients (see overlaid density plots for C(agecat).
The posterior for gender tells us that the claim amount tends to be larger for males than for females, with the mean being 0.153 and the credible interval ranging from 0.054 to 0.246.
Finally, from the marginal posteriors for the areas, we can see that F is the only area that clearly stands out, with a higher mean claim amount than in the rest. Area E may also have a higher claim amount, but this difference with the other areas is not as evident as it happens with F.
Gamma
model_gamma = bmb.Model(
"claimcst0 ~ agecat + gender + area",
data,
family="gamma",
link="log",
categorical="agecat",
)
fitted_gamma = model_gamma.fit(tune=2000, target_accept=0.9, idata_kwargs={"log_likelihood": True})Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [alpha, Intercept, agecat, gender, area]Sampling 4 chains for 2_000 tune and 1_000 draw iterations (8_000 + 4_000 draws total) took 17 seconds.az.plot_trace(fitted_gamma);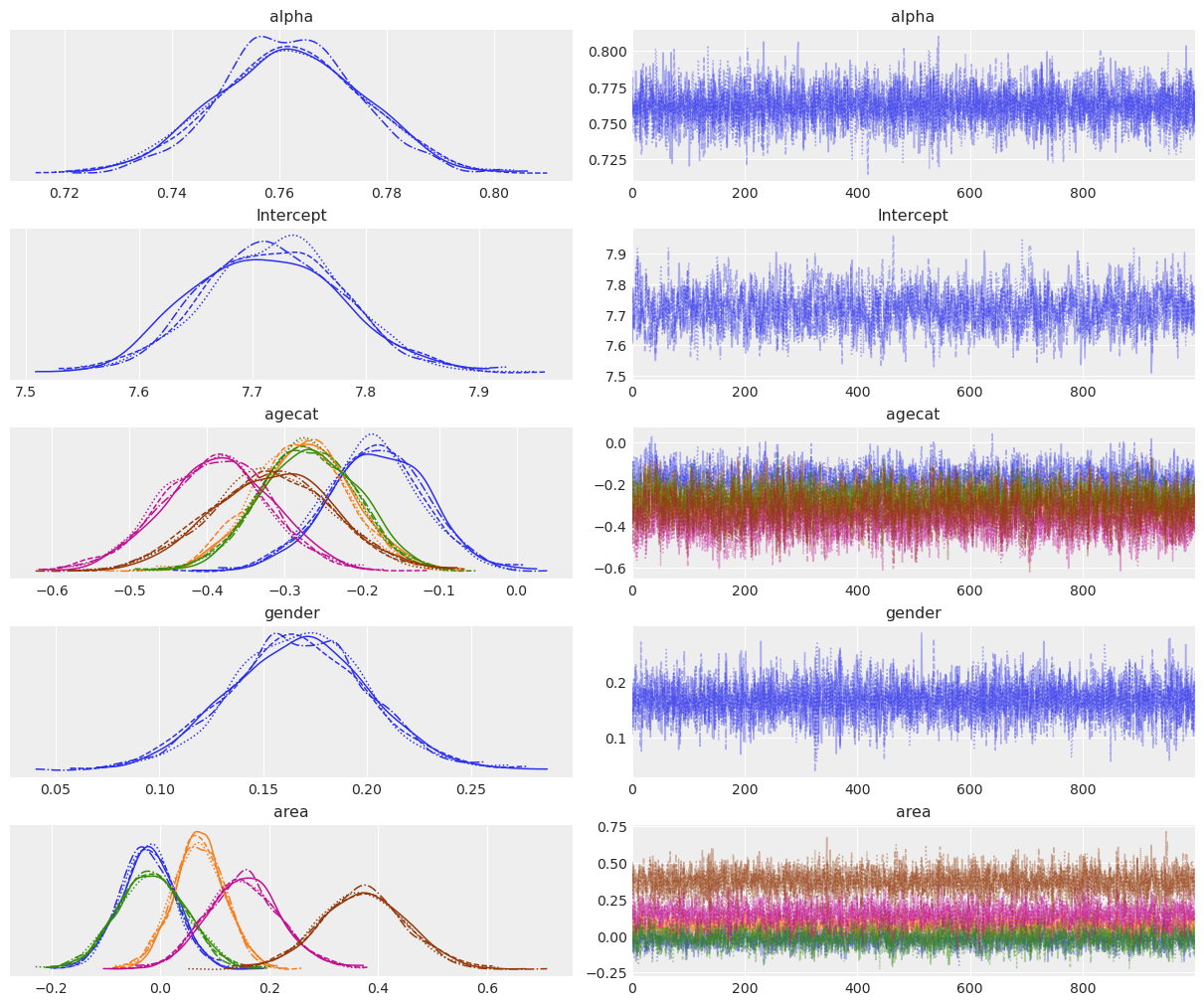
az.summary(fitted_gamma)| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| alpha | 0.762 | 0.013 | 0.737 | 0.788 | 0.000 | 0.000 | 5922.0 | 3167.0 | 1.0 |
| Intercept | 7.718 | 0.063 | 7.598 | 7.833 | 0.002 | 0.001 | 1556.0 | 2363.0 | 1.0 |
| agecat[2] | -0.183 | 0.064 | -0.309 | -0.067 | 0.002 | 0.001 | 1534.0 | 2426.0 | 1.0 |
| agecat[3] | -0.277 | 0.062 | -0.395 | -0.162 | 0.002 | 0.001 | 1625.0 | 2150.0 | 1.0 |
| agecat[4] | -0.270 | 0.062 | -0.382 | -0.150 | 0.002 | 0.001 | 1698.0 | 2049.0 | 1.0 |
| agecat[5] | -0.390 | 0.070 | -0.519 | -0.255 | 0.002 | 0.001 | 1684.0 | 2292.0 | 1.0 |
| agecat[6] | -0.317 | 0.080 | -0.463 | -0.165 | 0.002 | 0.001 | 2254.0 | 2648.0 | 1.0 |
| gender[M] | 0.167 | 0.033 | 0.106 | 0.231 | 0.000 | 0.001 | 6762.0 | 2939.0 | 1.0 |
| area[B] | -0.024 | 0.051 | -0.124 | 0.068 | 0.001 | 0.001 | 2704.0 | 2873.0 | 1.0 |
| area[C] | 0.071 | 0.048 | -0.021 | 0.157 | 0.001 | 0.001 | 2855.0 | 3221.0 | 1.0 |
| area[D] | -0.016 | 0.064 | -0.128 | 0.109 | 0.001 | 0.001 | 2951.0 | 2657.0 | 1.0 |
| area[E] | 0.152 | 0.069 | 0.031 | 0.290 | 0.001 | 0.001 | 3158.0 | 3269.0 | 1.0 |
| area[F] | 0.372 | 0.080 | 0.224 | 0.523 | 0.001 | 0.001 | 4019.0 | 2623.0 | 1.0 |
The interpretation of the parameter posteriors is very similar to what we’ve done for the Wald family. The only difference is that some differences, such as the ones for the area posteriors, are a little more exacerbated here.
Model comparison
We can perform a Bayesian model comparison very easily with az.compare(). Here we pass a dictionary with the InferenceData objects that Model.fit() returned and az.compare() returns a data frame that is ordered from best to worst according to the criteria used.
models = {"wald": fitted_wald, "gamma": fitted_gamma}
df_compare = az.compare(models)
df_compare| rank | elpd_loo | p_loo | elpd_diff | weight | se | dse | warning | scale | |
|---|---|---|---|---|---|---|---|---|---|
| wald | 0 | -38581.494055 | 12.959767 | 0.000000 | 1.0 | 106.043527 | 0.000000 | False | log |
| gamma | 1 | -39629.411646 | 27.222600 | 1047.917591 | 0.0 | 104.993558 | 35.785842 | False | log |
az.plot_compare(df_compare, insample_dev=False);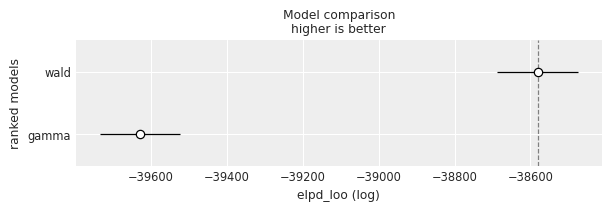
By default, ArviZ uses loo, which is an estimation of leave one out cross-validation. Another option is the widely applicable information criterion (WAIC). Since the results are in the log scale, the better out-of-sample predictive fit is given by the model with the highest value, which is the Wald model.
%load_ext watermark
%watermark -n -u -v -iv -wLast updated: Sun Sep 28 2025
Python implementation: CPython
Python version : 3.13.7
IPython version : 9.4.0
matplotlib: 3.10.6
arviz : 0.22.0
bambi : 0.14.1.dev58+gb25742785.d20250928
Watermark: 2.5.0