import arviz as az
import bambi as bmb
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
az.style.use("arviz-darkgrid")
SEED = 121195Logistic Regression (Vote intention with ANES data)
Load and examine American National Election Studies (ANES) data
These data are from the 2016 pilot study. The full study consisted of 1200 people, but here we’ve selected the subset of 487 people who responded to a question about whether they would vote for Hillary Clinton or Donald Trump.
data = bmb.load_data("ANES")
data.head()| vote | age | party_id | |
|---|---|---|---|
| 0 | clinton | 56 | democrat |
| 1 | trump | 65 | republican |
| 2 | clinton | 80 | democrat |
| 3 | trump | 38 | republican |
| 4 | trump | 60 | republican |
Our outcome variable is vote, which gives peoples’ responses to the following question prompt:
“If the 2016 presidential election were between Hillary Clinton for the Democrats and Donald Trump for the Republicans, would you vote for Hillary Clinton, Donald Trump, someone else, or probably not vote?”
data["vote"].value_counts()vote
clinton 215
trump 158
someone_else 48
Name: count, dtype: int64The two predictors we’ll examine are a respondent’s age and their political party affiliation, party_id, which is their response to the following question prompt:
“Generally speaking, do you usually think of yourself as a Republican, a Democrat, an independent, or what?”
data["party_id"].value_counts()party_id
democrat 186
independent 138
republican 97
Name: count, dtype: int64These two predictors are somewhat correlated, but not all that much:
fig, ax = plt.subplots(1, 3, figsize=(10, 4), sharey=True, constrained_layout=True)
key = dict(zip(data["party_id"].unique(), range(3)))
for label, df in data.groupby("party_id"):
ax[key[label]].hist(df["age"])
ax[key[label]].set_xlim([18, 90])
ax[key[label]].set_xlabel("Age")
ax[key[label]].set_ylabel("Frequency")
ax[key[label]].set_title(label)
ax[key[label]].axvline(df["age"].mean(), color="C1")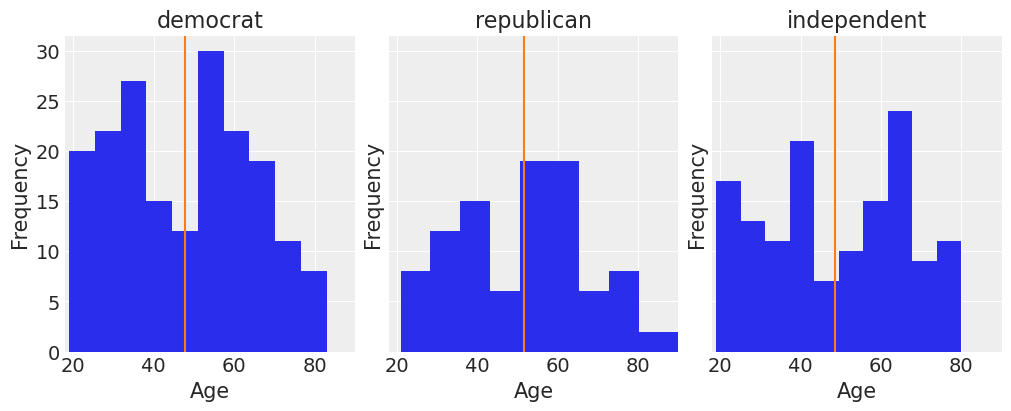
We can get a pretty clear idea of how party identification is related to voting intentions by just looking at a contingency table for these two variables:
pd.crosstab(data["vote"], data["party_id"])| party_id | democrat | independent | republican |
|---|---|---|---|
| vote | |||
| clinton | 159 | 51 | 5 |
| someone_else | 10 | 22 | 16 |
| trump | 17 | 65 | 76 |
But our main question here will be: How is respondent age related to voting intentions, and is this relationship different for different party affiliations? For this we will use a logistic regression.
Build clinton_model
To keep this simple, let’s look at only the data from people who indicated that they would vote for either Clinton or Trump, and we’ll model the probability of voting for Clinton.
clinton_data = data.loc[data["vote"].isin(["clinton", "trump"]), :]
clinton_data.head()| vote | age | party_id | |
|---|---|---|---|
| 0 | clinton | 56 | democrat |
| 1 | trump | 65 | republican |
| 2 | clinton | 80 | democrat |
| 3 | trump | 38 | republican |
| 4 | trump | 60 | republican |
Logistic regression
We’ll use a logistic regression model to estimate the probability of voting for Clinton as a function of age and party affiliation. We can think we have a response variable \(Y\) defined as
\[ Y = \left\{ \begin{array}{ll} 1 & \textrm{if the person votes for Clinton} \\ 0 & \textrm{if the person votes for Trump} \end{array} \right. \]
and we are interested in modelling \(\pi = P(Y = 1)\) (a.k.a. probability of success) based on two explanatory variables, age and party affiliation.
A logistic regression is a model that links the \(\text{logit}(\pi)\) to a linear combination of the predictors. In our example, we’re going to include a main effect for party affiliation and the interaction effect between party affiliation and age (i.e. we’ll have a different age slope for each affiliation). The mathematical equation for our model is
\[ \begin{aligned} \log{\left(\frac{\pi}{1 - \pi}\right)} &= \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \beta_3 X_3 X_4 + \beta_4 X_1 X_4 + \beta_5 X_2 X_4 \\ X_1 &= \left\{ \begin{array}{ll} 1 & \textrm{if party affiliation is Independent} \\ 0 & \textrm{in other case} \end{array} \right. \\ X_2 &= \left\{ \begin{array}{ll} 1 & \textrm{if party affiliation is Republican} \\ 0 & \textrm{in other case} \end{array} \right. \\ X_3 &= \left\{ \begin{array}{ll} 1 & \textrm{if party affiliation is Democrat} \\ 0 & \textrm{in other case} \end{array} \right. \\ X_4 &= \text{Age} \end{aligned} \]
Notice we don’t have a main effect for \(X_3\). This happens because Democrat party affiliation is being taken as baseline in the encoding of the categorical variable party_id and \(\beta_1\) and \(\beta_2\) represent deviations from that baseline. Thus, we see the main effect of Democrat affiliation is being represented by the Intercept, \(\beta_0\).
If we represent the right hand side of the model equation with \(\eta\), the expression can be re-arranged to express our probability of interest, \(\pi\), as a function of the linear predictor \(\eta\).
\[\pi = \frac{e^\eta}{1 + e^\eta}= \frac{1}{1 + e^{-\eta}}\]
Since we’re Bayesian folks who draw samples from posteriors, we need to specify a prior for the parameters as well as a likelihood function before accomplishing our task. In this occasion, we’re going to use the default priors in Bambi and just note the likelihood is the product of \(n\) Bernoulli trials, \(\prod_{i=1}^{n}{p_i^y(1-p_i)^{1-y_i}}\) where \(p_i = P(Y=1)\) and \(y_i = 1\) if the vote intention is for Clinton and \(y_i = 0\) if Trump.
Specify and fit model in Bambi
Specifying and fitting the model is simple. Bambi is good and doesn’t ask us to translate all the math to code. We just need to specify our model using the formula syntax and pass the correct family argument. Notice the (optional) syntax that we use on the left-hand-side of the formula: We say vote[clinton] to instruct Bambi that we wish the model the probability that vote=='clinton', rather than the probability that vote=='trump'. If we leave this unspecified, Bambi will just pick one of the events to model, but will inform you which one it picked when you build the model (and again when you look at model summaries).
On the right-hand-side of the formula we use party_id + party_id:age to instruct Bambi that we want to use party_id and the interaction between party_id and age as the explanatory variables in the model.
clinton_model = bmb.Model("vote['clinton'] ~ party_id + party_id:age", clinton_data, family="bernoulli")
clinton_fitted = clinton_model.fit(
draws=2000, target_accept=0.85, random_seed=SEED, idata_kwargs={"log_likelihood": True}
)Modeling the probability that vote==clinton
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [Intercept, party_id, party_id:age]Sampling 4 chains for 1_000 tune and 2_000 draw iterations (4_000 + 8_000 draws total) took 5 seconds.We can print the model object to see information about the response distribution, the link function and the priors.
clinton_model Formula: vote['clinton'] ~ party_id + party_id:age
Family: bernoulli
Link: p = logit
Observations: 373
Priors:
target = p
Common-level effects
Intercept ~ Normal(mu: 0.0, sigma: 1.5)
party_id ~ Normal(mu: [0. 0.], sigma: [1. 1.])
party_id:age ~ Normal(mu: [0. 0. 0.], sigma: [0.0582 0.0582 0.0582])
------
* To see a plot of the priors call the .plot_priors() method.
* To see a summary or plot of the posterior pass the object returned by .fit() to az.summary() or az.plot_trace()Under the hood, Bambi selected Gaussian priors for all the parameters in the model. By construction, all the priors, except the one for Intercept, are centered around 0, which is consistent with the desired weakly informative behavior. The standard deviation is specific to each parameter.
Some more info about these default priors can be found in this technical paper.
We can also call clinton_model.plot_priors() to visualize the sensitive default priors Bambi has chosen for us.
clinton_model.plot_priors();Sampling: [Intercept, party_id, party_id:age]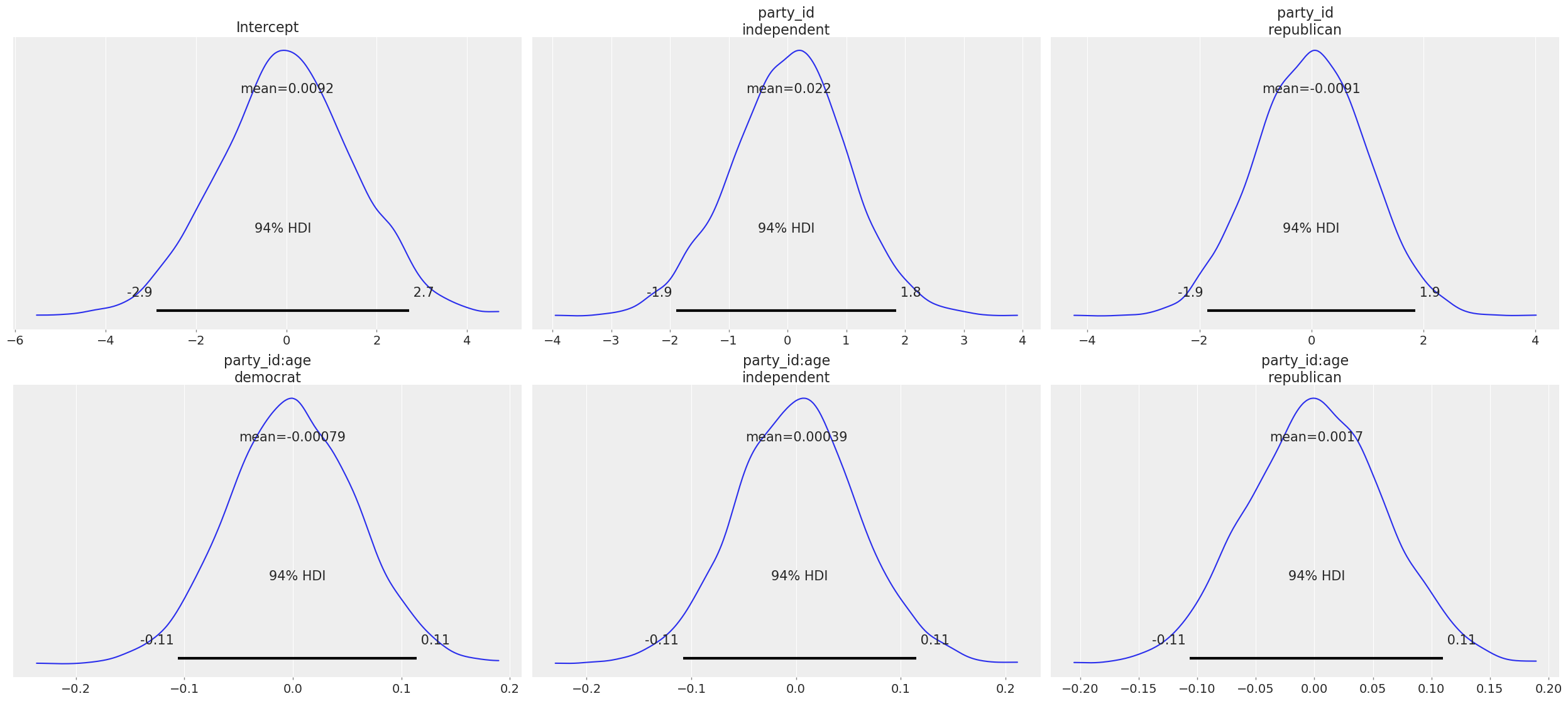
Now let’s check out the results! We get traceplots and density estimates for the posteriors with az.plot_trace() and a summary of the posteriors with az.summary().
az.plot_trace(clinton_fitted, compact=False);
az.summary(clinton_fitted)| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| Intercept | 1.395 | 0.569 | 0.329 | 2.466 | 0.007 | 0.006 | 6654.0 | 5499.0 | 1.0 |
| party_id[independent] | -0.037 | 0.652 | -1.189 | 1.235 | 0.008 | 0.008 | 5920.0 | 4701.0 | 1.0 |
| party_id[republican] | -0.615 | 0.818 | -2.205 | 0.881 | 0.011 | 0.010 | 5579.0 | 5042.0 | 1.0 |
| party_id:age[democrat] | 0.018 | 0.012 | -0.004 | 0.043 | 0.000 | 0.000 | 6209.0 | 4699.0 | 1.0 |
| party_id:age[independent] | -0.033 | 0.011 | -0.052 | -0.013 | 0.000 | 0.000 | 6277.0 | 5047.0 | 1.0 |
| party_id:age[republican] | -0.082 | 0.024 | -0.128 | -0.039 | 0.000 | 0.000 | 5360.0 | 3984.0 | 1.0 |
Model assessment
Before moving forward to inference, we can evaluate the quality of the model’s fit. We will take a look at two different ways of assessing how good is the model’s fit using its predictions.
Separation plot
There is a way of assessing the performance of a model with binary outcomes (such as logistic regression) in a visual way called separation plot. In a separation plot, the model’s predictions are averaged, ordered and represented as consecutive vertical lines. These vertical lines are colored according to the class indicated by their corresponding observed value, in this case light blue indicates class 0 (vote == 'Trump') and blue represents class 1 (vote =='Clinton'). We can use the ArviZ’ implementation of the separation plot, but first we have to obtain the model’s predictions.
clinton_model.predict(clinton_fitted, kind="response")ax = az.plot_separation(clinton_fitted, y="vote", figsize=(9,0.5));
In this separation plot we can see that some observations are misspredicted, specially in the right hand side of the plot where the model predicts Trump votes when there were really Clinton ones. We can further investigate this using another of ArviZ model evaluation tool.
\(\hat \kappa\) parameter
We can also use ArviZ to compute LOO and find influential observations using the estimated \(\hat \kappa\) parameter value.
# compute pointwise LOO
loo = az.loo(clinton_fitted, pointwise=True)# plot kappa values
az.plot_khat(loo.pareto_k);/home/tomas/oss/bambinos/bambi/.pixi/envs/dev/lib/python3.13/site-packages/arviz/plots/khatplot.py:184: FutureWarning: support for DataArrays will be deprecated, please use ELPDData.The reason for this, is that we need to know the numbers of drawssampled from the posterior
warnings.warn(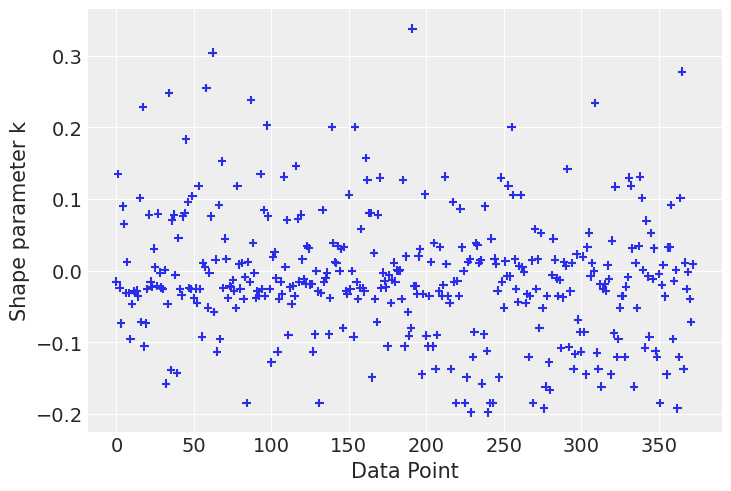
A first look at the khat plot shows that most observations’ \(\hat \kappa\) values are grouped together in a range that goes up to roughly 0.2. Above that value, we observe some dispersion and a few points that stand out by having the highest \(\hat \kappa\) values.
An observation is influential in the sense that if we refit the data by first removing that observation from the data set, the fitted result will be more different than if we do the same for a non influential observation. Clearly the level of influence of observations can vary continuously. An observation can be influential either because it is an outlier (a measurement error, a data entry error, etc) or because the model is not flexible enough to capture the observation. The approximations used to compute LOO are no longer reliable for \(\hat \kappa > 0.7\).
Let us first take a look at the observation with the highest \(\hat \kappa\).
ax = az.plot_khat(loo.pareto_k.values.ravel())
sorted_kappas = np.sort(loo.pareto_k.values.ravel())
# find observation where the kappa value exceeds the threshold
threshold = sorted_kappas[-1:]
ax.axhline(threshold, ls="--", color="orange")
influential_observations = clinton_data.reset_index()[loo.pareto_k.values >= threshold].index
for x in influential_observations:
y = loo.pareto_k.values[x]
ax.text(x, y + 0.01, str(x), ha="center", va="baseline")/home/tomas/oss/bambinos/bambi/.pixi/envs/dev/lib/python3.13/site-packages/arviz/plots/khatplot.py:167: FutureWarning: support for arrays will be deprecated, please use ELPDData.The reason for this, is that we need to know the numbers of drawssampled from the posterior
warnings.warn(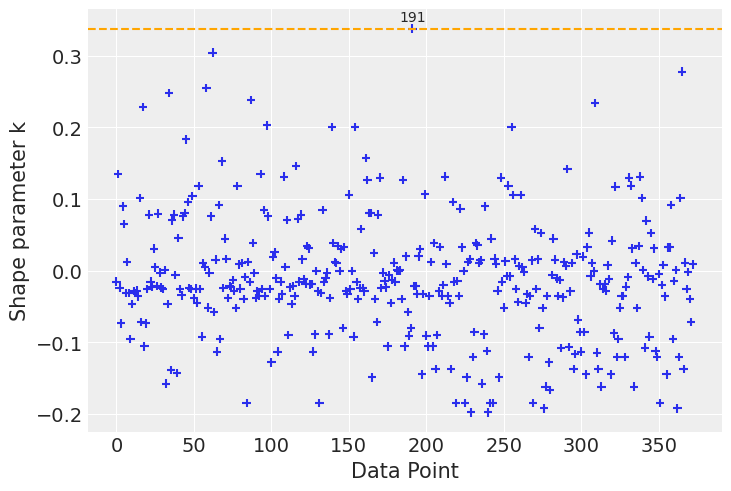
clinton_data.reset_index()[loo.pareto_k.values >= threshold]| index | vote | age | party_id | |
|---|---|---|---|---|
| 191 | 215 | trump | 95 | republican |
This observation corresponds to a 95 year old Republican party member that voted for Trump.
Let us take a look at six observations with the highest \(\hat \kappa\) values.
ax = az.plot_khat(loo.pareto_k)
# find observation where the kappa value exceeds the threshold
threshold = sorted_kappas[-6:].min()
ax.axhline(threshold, ls="--", color="orange")
influential_observations = clinton_data.reset_index()[loo.pareto_k.values >= threshold].index
for x in influential_observations:
y = loo.pareto_k.values[x]
ax.text(x, y + 0.01, str(x), ha="center", va="baseline")/home/tomas/oss/bambinos/bambi/.pixi/envs/dev/lib/python3.13/site-packages/arviz/plots/khatplot.py:184: FutureWarning: support for DataArrays will be deprecated, please use ELPDData.The reason for this, is that we need to know the numbers of drawssampled from the posterior
warnings.warn(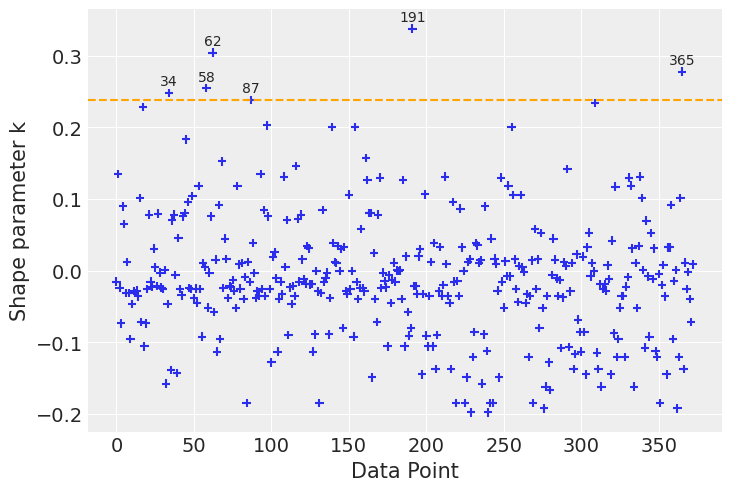
clinton_data.reset_index()[loo.pareto_k.values>=threshold]| index | vote | age | party_id | |
|---|---|---|---|---|
| 34 | 34 | trump | 83 | republican |
| 58 | 64 | trump | 84 | republican |
| 62 | 68 | trump | 91 | republican |
| 87 | 95 | trump | 80 | republican |
| 191 | 215 | trump | 95 | republican |
| 365 | 410 | clinton | 55 | republican |
Observations number 34, 58, 62, and 191 correspond to individuals in under represented age groups in the data set. The rest correspond to Republican party members that voted for Clinton. Let us check how many observations we have of individuals older than 80 years old.
clinton_data[clinton_data.age > 80]| vote | age | party_id | |
|---|---|---|---|
| 34 | trump | 83 | republican |
| 64 | trump | 84 | republican |
| 68 | trump | 91 | republican |
| 97 | clinton | 83 | democrat |
| 215 | trump | 95 | republican |
| 246 | clinton | 82 | democrat |
| 403 | clinton | 81 | democrat |
Let us check how many observations there are of Republicans who voted for Clinton
clinton_data[(clinton_data.vote =='clinton') & (clinton_data.party_id == 'republican')]| vote | age | party_id | |
|---|---|---|---|
| 170 | clinton | 27 | republican |
| 248 | clinton | 36 | republican |
| 359 | clinton | 22 | republican |
| 361 | clinton | 37 | republican |
| 410 | clinton | 55 | republican |
There are only two observations for individuals older than 80 years old and five observations for individuals of the Republican party that vote for Clinton. The fact that the model finds it difficult to predict for these observations is related to model uncertainty, due to a scarce number of observations that exhibit these characteristics.
Let us repeat the separation plot, this time marking the observations we have analyzed. This plot will show us how the model predicted these particular observations.
import matplotlib.patheffects as pe
ax = az.plot_separation(clinton_fitted, y="vote", figsize=(9, 0.5))
y = np.random.uniform(0.1, 0.5, size=len(influential_observations))
for x, y in zip(influential_observations, y):
text = str(x)
x = x / len(clinton_data)
ax.scatter(x, y, marker="+", s=50, color="red", zorder=3)
ax.text(
x, y + 0.1, text, color="white", ha="center", va="bottom",
path_effects=[pe.withStroke(linewidth=2, foreground="black")]
)
clinton_data.reset_index()[loo.pareto_k.values>=threshold]| index | vote | age | party_id | |
|---|---|---|---|---|
| 34 | 34 | trump | 83 | republican |
| 58 | 64 | trump | 84 | republican |
| 62 | 68 | trump | 91 | republican |
| 87 | 95 | trump | 80 | republican |
| 191 | 215 | trump | 95 | republican |
| 365 | 410 | clinton | 55 | republican |
This assessment helped us to further understand the model and quality of the fit. It also illustrates the intuition that we should be cautious when predicting for under represented age groups and voting behaviours.
Run Inference
Grab the posteriors samples of the age slopes for the three party_id categories.
parties = ["democrat", "independent", "republican"]
dem, ind, rep = [clinton_fitted.posterior["party_id:age"].sel({"party_id:age_dim":party}) for party in parties]Plot the marginal posteriors for the age slopes for the three political affiliations.
_, ax = plt.subplots()
for idx, x in enumerate([dem, ind, rep]):
az.plot_dist(x, label=x["party_id:age_dim"].item(), plot_kwargs={"color": f"C{idx}"}, ax=ax)
ax.legend(loc="upper left");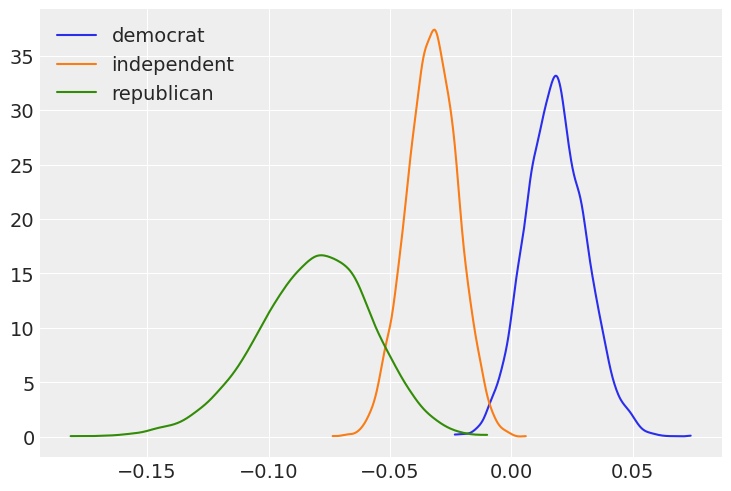
Now, using the joint posterior, we can answer our questions in terms of probabilities.
What is the probability that the Democrat slope is greater than the Republican slope?
(dem > rep).mean().item()1.0Probability that the Democrat slope is greater than the Independent slope?
(dem > ind).mean().item()1.0Probability that the Independent slope is greater than the Republican slope?
(ind > rep).mean().item()0.97775Probability that the Democrat slope is greater than 0?
(dem > 0).mean().item()0.935875Probability that the Republican slope is less than 0?
(rep < 0).mean().item()1.0Probability that the Independent slope is less than 0?
(ind < 0).mean().item()0.99975If we look at the plot of the marginal posteriors, we may be suspicious that, for example, the probability that Democrat slope is greater than the Republican slope is 0.998 (almost 1!), given the overlap between the blue and green density functions. However, we can’t answer such a question using the marginal posteriors only, as shown in the plot. Since Democrat and Republican slopes (\(\beta_3\) and \(\beta_5\), respectively) are random variables, we need to use their joint distribution to answer probability questions that involve both of them. The fact that logical comparisons (e.g. > in dem > ind) are performed elementwise ensures we’re using samples from the joint posterior as we should. We also note that when the question involves only one of the random variables, it is fine to use the marginal distribution (e.g. (rep < 0).mean()).
Finally, all these comments may have not been necessary since we didn’t need to mention anything about marginal or joint distributions when performing the calculations, we’ve just grabbed the samples and applied some basic math. But that’s an advantage of Bambi and the Bayesian approach. Things that are not so simple, became simpler :)
Spaghetti plot of model predictions
Here we make use of the Model.predict() method to predict the probability of voting for Clinton for an out-of-sample dataset that we create.
age = np.arange(18, 91)
new_data = pd.DataFrame({
"age": np.tile(age, 3),
"party_id": np.repeat(["democrat", "republican", "independent"], len(age))
})
new_data| age | party_id | |
|---|---|---|
| 0 | 18 | democrat |
| 1 | 19 | democrat |
| 2 | 20 | democrat |
| 3 | 21 | democrat |
| 4 | 22 | democrat |
| ... | ... | ... |
| 214 | 86 | independent |
| 215 | 87 | independent |
| 216 | 88 | independent |
| 217 | 89 | independent |
| 218 | 90 | independent |
219 rows × 2 columns
Obtain predictions for the new dataset. By default, Bambi is going to obtain a posterior distribution for the mean probability of voting for Clinton. These values are stored as the "p" variable in clinton_fitted.posterior.
clinton_model.predict(clinton_fitted, data=new_data)# Select a sample of posterior values for the mean probability of voting for Clinton
vote_posterior = az.extract(clinton_fitted, num_samples=2000)["p"]Make the plot!
_, ax = plt.subplots(figsize=(7, 5))
for i, party in enumerate(["democrat", "republican", "independent"]):
# Which rows in new_data correspond to party?
idx = new_data.index[new_data["party_id"] == party].tolist()
ax.plot(age, vote_posterior[idx], alpha=0.04, color=f"C{i}")
ax.set_ylabel("P(vote='clinton' | age)")
ax.set_xlabel("Age", fontsize=15)
ax.set_ylim(0, 1)
ax.set_xlim(18, 90);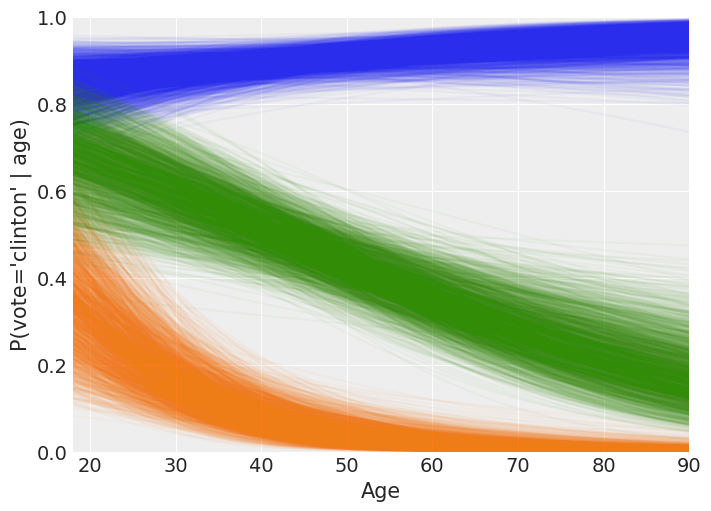
The following is a rough interpretation of the information contained in the plot we’ve just created.
According to our logistic model, the mean probability of voting for Clinton is almost always 0.8 or greater for Democrats no matter the age (blue line). Also, the older the person, the closer the mean probability of voting Clinton to 1.
On the other hand, Republicans have a non-zero probability of voting for Clinton when they are young, but it tends to zero for older persons (green line). We can also note the high variability of P(vote = ‘Clinton’) for young Republicans. This reflects our high uncertainty when estimating this probability and it is due to the small amount of Republicans in that age range plus there are only 5 Republicans out of 97 voting for Clinton in the dataset.
Finally, the mean probability of voting Clinton for the independents is around 0.7 for the youngest and decreases towards 0.2 as they get older (orange line). Since the spread of the lines is similar along all the ages, we can conclude our uncertainty in this estimate is similar for all the age groups.
%load_ext watermark
%watermark -n -u -v -iv -wLast updated: Sun Sep 28 2025
Python implementation: CPython
Python version : 3.13.7
IPython version : 9.4.0
matplotlib: 3.10.6
pandas : 2.3.2
bambi : 0.14.1.dev57+g7b2bb342c.d20250928
arviz : 0.22.0
numpy : 2.3.3
Watermark: 2.5.0