import arviz as az
import bambi as bmb
import matplotlib.pyplot as plt
import numpy as np
import pandas as pdMultilevel Regression and Post-stratification
Regression and Effect Modification
What are we even doing when we fit a regression model? Is a question that arises when first learning the tools of the trade and again when debugging strange results of your thousandth logistic regression model.
This notebook is intended to showcase how regression can be seen as a method for automating the calculation of stratum specific conditional effects. Additionally, we’ll see how we can enrich regression models by a post-stratification adjustment with knowledge of the appropriate stratum specific weights. This technique of multilevel regression and post stratification (MrP) is often used in the context of national surveys where we have knowledge of the population weights appropriate to different demographic groups. It can be used in a wide variety of areas ranging from political polling to online market research. We will demonstrate how to fit and and assess these models using Bambi.
Risk Stratification
First consider this example of heart transplant patients adapted from Hernan and Robins’ excellent book Causal Inference: What if. Here we have a number of patients (anonymised with names for the Greek Gods). The data records the outcomes of a heart transplant program for those who were part of the program and those who were not. We also see the different risk levels of each patient assigned the treatment.
What we want to show here is that a regression model fit to this data automatically accounts for the weighting appropriate to the different risk strata. The data is coded with 0-1 indicators for status. Risk_Strata is either 1 for higher risk or 0 for lower risk. Outcome is whether or not the patient died from the procedure, and Treatment is whether or not the patient received treatment.
df = pd.DataFrame(
{
"name": [
"Rheia",
"Kronos",
"Demeter",
"Hades",
"Hestia",
"Poseidon",
"Hera",
"Zeus",
"Artemis",
"Apollo",
"Leto",
"Ares",
"Athena",
"Hephaestus",
"Aphrodite",
"Cyclope",
"Persephone",
"Hermes",
"Hebe",
"Dionysus",
],
"Risk_Strata": [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
"Treatment": [0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1],
"Outcome": [0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0],
}
)
df["Treatment_x_Risk_Strata"] = df.Treatment * df.Risk_Strata
df| name | Risk_Strata | Treatment | Outcome | Treatment_x_Risk_Strata | |
|---|---|---|---|---|---|
| 0 | Rheia | 0 | 0 | 0 | 0 |
| 1 | Kronos | 0 | 0 | 1 | 0 |
| 2 | Demeter | 0 | 0 | 0 | 0 |
| 3 | Hades | 0 | 0 | 0 | 0 |
| 4 | Hestia | 0 | 1 | 0 | 0 |
| 5 | Poseidon | 0 | 1 | 0 | 0 |
| 6 | Hera | 0 | 1 | 0 | 0 |
| 7 | Zeus | 0 | 1 | 1 | 0 |
| 8 | Artemis | 1 | 0 | 1 | 0 |
| 9 | Apollo | 1 | 0 | 1 | 0 |
| 10 | Leto | 1 | 0 | 0 | 0 |
| 11 | Ares | 1 | 1 | 1 | 1 |
| 12 | Athena | 1 | 1 | 1 | 1 |
| 13 | Hephaestus | 1 | 1 | 1 | 1 |
| 14 | Aphrodite | 1 | 1 | 1 | 1 |
| 15 | Cyclope | 1 | 1 | 1 | 1 |
| 16 | Persephone | 1 | 1 | 1 | 1 |
| 17 | Hermes | 1 | 1 | 0 | 1 |
| 18 | Hebe | 1 | 1 | 0 | 1 |
| 19 | Dionysus | 1 | 1 | 0 | 1 |
If the treatment assignment procedure involved complete randomisation then we might expect a reasonable balance of strata effects across the treated and non-treated. In this sample we see (perhaps counter intuitively) that the treatment seems to induce a higher rate of death than the non-treated group.
simple_average = df.groupby("Treatment")[["Outcome"]].mean().rename({"Outcome": "Share"}, axis=1)
simple_average| Share | |
|---|---|
| Treatment | |
| 0 | 0.428571 |
| 1 | 0.538462 |
Which suggests an alarming causal effect whereby the treatment seems to increase risk of death in the population.
causal_risk_ratio = simple_average.iloc[1]["Share"] / simple_average.iloc[0]["Share"]
print("Causal Risk Ratio:", causal_risk_ratio)Causal Risk Ratio: 1.2564102564102564This finding we know on inspection is driven by the imbalance in the risk strata across the treatment groups.
df.groupby("Risk_Strata")[["Treatment"]].count().assign(
proportion=lambda x: x["Treatment"] / len(df)
)| Treatment | proportion | |
|---|---|---|
| Risk_Strata | ||
| 0 | 8 | 0.4 |
| 1 | 12 | 0.6 |
We can correct for this by weighting the results by the share each group represents across the Risk_Strata. In other words when we correct for the population size at the different levels of risk we get a better estimate of the effect. First we see what the expected outcome is for each strata.
outcomes_controlled = (
df.groupby(["Risk_Strata", "Treatment"])[["Outcome"]]
.mean()
.reset_index()
.pivot(index="Treatment", columns=["Risk_Strata"], values="Outcome")
)
outcomes_controlled| Risk_Strata | 0 | 1 |
|---|---|---|
| Treatment | ||
| 0 | 0.25 | 0.666667 |
| 1 | 0.25 | 0.666667 |
Note how the expected outcomes are equal across the stratified groups. We can now combine these estimate with the population weights (derived earlier) in each segment to get our weighted average.
weighted_avg = outcomes_controlled.assign(formula="0.4*0.25 + 0.6*0.66").assign(
weighted_average=lambda x: x[0] * (df[df["Risk_Strata"] == 0].shape[0] / len(df))
+ x[1] * (df[df["Risk_Strata"] == 1].shape[0] / len(df))
)
weighted_avg| Risk_Strata | 0 | 1 | formula | weighted_average |
|---|---|---|---|---|
| Treatment | ||||
| 0 | 0.25 | 0.666667 | 0.4*0.25 + 0.6*0.66 | 0.5 |
| 1 | 0.25 | 0.666667 | 0.4*0.25 + 0.6*0.66 | 0.5 |
From which we can derive a more sensible treatment effect.
causal_risk_ratio = (
weighted_avg.iloc[1]["weighted_average"] / weighted_avg.iloc[0]["weighted_average"]
)
print("Causal Risk Ratio:", causal_risk_ratio)Causal Risk Ratio: 1.0Regression as Stratification
So far, so good. But so what?
The point here is that the above series of steps can be difficult to accomplish with more complex sets of groups and risk profiles. So it’s useful to understand that regression can be used to automatically account for the variation in outcome effects across the different strata of our population. More prosaically, the example shows that it really matters what variables you put in your model.
reg = bmb.Model("Outcome ~ 1 + Treatment", df)
results = reg.fit()
reg_strata = bmb.Model("Outcome ~ 1 + Treatment + Risk_Strata + Treatment_x_Risk_Strata", df)
results_strata = reg_strata.fit()Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [sigma, Intercept, Treatment]Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 1 seconds.
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [sigma, Intercept, Treatment, Risk_Strata, Treatment_x_Risk_Strata]Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 1 seconds.We can now inspect the treatment effect and the implied causal risk ratio in each model. We can quickly recover that controlling for the right variables in our regression model automatically adjusts the treatment effect downwards towards 0.
az.summary(results)| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| sigma | 0.543 | 0.096 | 0.388 | 0.721 | 0.002 | 0.002 | 3421.0 | 2579.0 | 1.0 |
| Intercept | 0.428 | 0.208 | 0.052 | 0.834 | 0.003 | 0.004 | 4026.0 | 2958.0 | 1.0 |
| Treatment | 0.110 | 0.255 | -0.387 | 0.600 | 0.004 | 0.005 | 3604.0 | 2690.0 | 1.0 |
az.summary(results_strata)| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| sigma | 0.531 | 0.099 | 0.364 | 0.719 | 0.002 | 0.002 | 2324.0 | 1914.0 | 1.0 |
| Intercept | 0.254 | 0.260 | -0.249 | 0.720 | 0.005 | 0.004 | 2523.0 | 2713.0 | 1.0 |
| Treatment | 0.000 | 0.367 | -0.715 | 0.650 | 0.008 | 0.007 | 2029.0 | 2319.0 | 1.0 |
| Risk_Strata | 0.408 | 0.401 | -0.342 | 1.145 | 0.008 | 0.007 | 2321.0 | 2513.0 | 1.0 |
| Treatment_x_Risk_Strata | -0.003 | 0.499 | -0.981 | 0.887 | 0.011 | 0.010 | 1920.0 | 2230.0 | 1.0 |
ax = az.plot_forest(
[results, results_strata],
model_names=["naive_model", "stratified_model"],
var_names=["Treatment"],
kind="ridgeplot",
ridgeplot_alpha=0.4,
combined=True,
figsize=(10, 6),
)
ax[0].axvline(0, color="black", linestyle="--")
ax[0].set_title("Treatment Effects under Stratification/Non-stratification");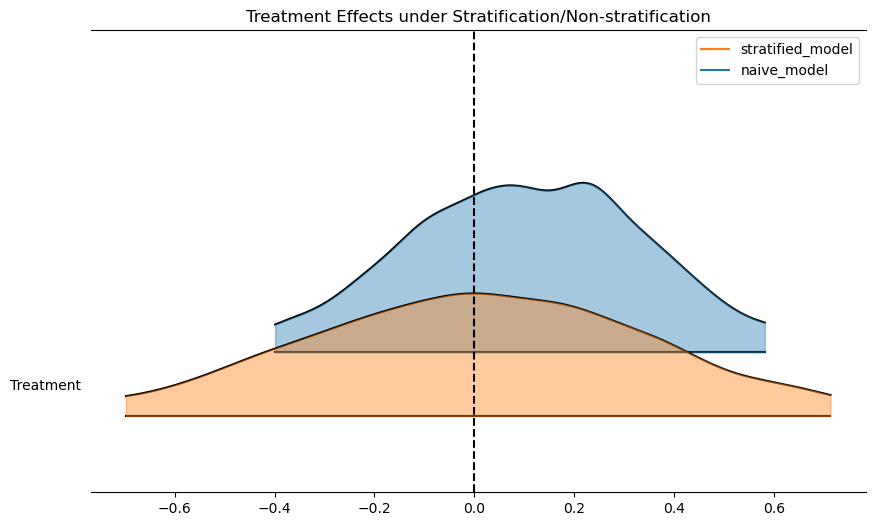
We can even see this in the predicted outcomes for the model. This is an important step. The regression model automatically adjusts for the risk profile within the appropriate strata in the data “seen” by the model.
new_df = df[["Risk_Strata"]].assign(Treatment=1).assign(Treatment_x_Risk_Strata=1)
new_preds = reg_strata.predict(results_strata, kind="response", data=new_df, inplace=False)
print("Expected Outcome in the Treated")
new_preds["posterior_predictive"]["Outcome"].mean().item()Expected Outcome in the Treated0.49444377057220107new_df = df[["Risk_Strata"]].assign(Treatment=0).assign(Treatment_x_Risk_Strata=0)
new_preds = reg_strata.predict(results_strata, kind="pps", data=new_df, inplace=False)
print("Expected Outcome in the Untreated")
new_preds["posterior_predictive"]["Outcome"].mean().item()Expected Outcome in the Untreated/home/tomas/Desktop/oss/bambinos/bambi/bambi/models.py:924: FutureWarning: 'pps' has been replaced by 'response' and is not going to work in the future
warnings.warn(0.4986805221639267We can see these results more clearly using bambi model interpretation functions to see the predictions within a specific strata.
fig, axs = plt.subplots(1, 2, figsize=(20, 6))
p1 = bmb.interpret.plot_predictions(
reg,
results,
["Treatment"],
fig_kwargs={"title": "Non Stratified Regression \n Model Predictions"}
)
p2 = bmb.interpret.plot_predictions(
reg_strata,
results_strata,
["Treatment"],
fig_kwargs={"title": "Stratified Regression \n Model Predictions"}
)
p1.on(axs[0]).plot()
p2.on(axs[1]).plot().show()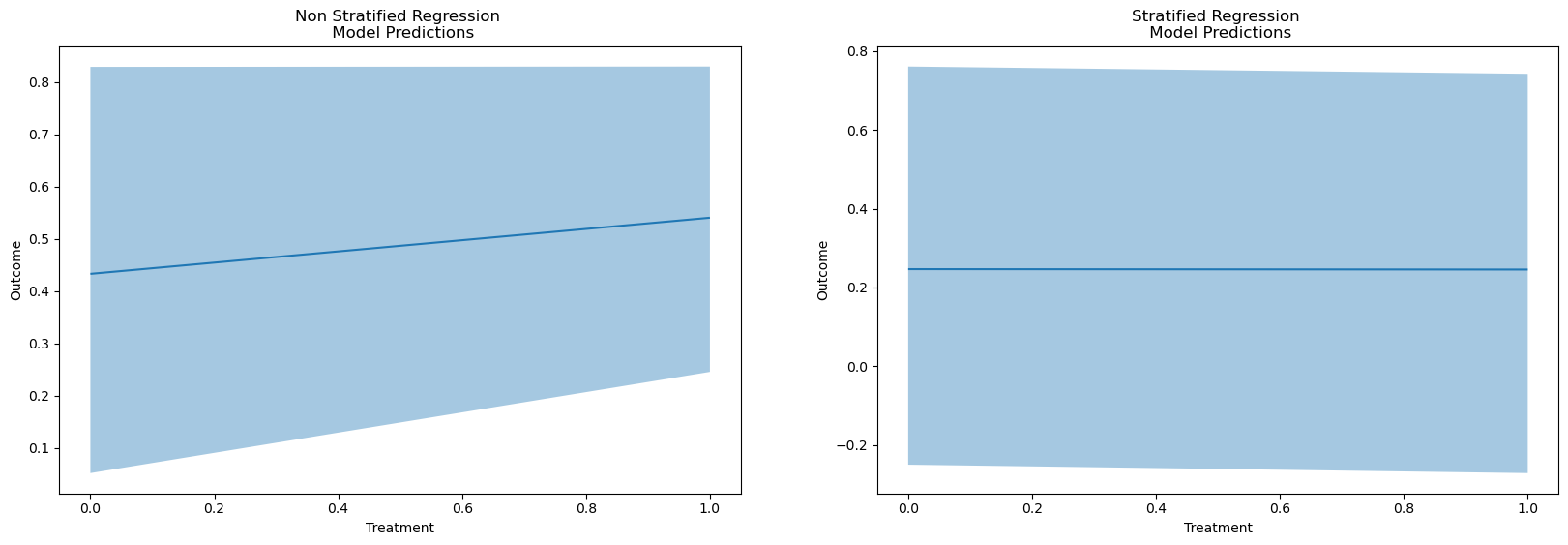
Hernan and Robins expand on these foundational observations and elaborate the implications for causal inference and the bias of confounding variables. We won’t go into these details, as we instead we want to draw out the connection with controlling for the risk of non-representative sampling. The usefulness of “representative-ness” as an idea is disputed in the statistical literature due to the vagueness of the term. To say a sample is representative is ussually akin to meaning that it was generated from a high-quality probability sampling design. This design is specified to avoid the creep of bias due to selection effects contaminating the results.
We’ve seen how regression can automate stratification across the levels of covariates in the model conditional on the sample data. But what if the prevalence of the risk-profile in your data does not reflect the prevalance of risk in the wider population? Then the regression model will automatically adjust to the prevalence in the sample, but it is not adjusting to the correct weights.
The Need for Post-Stratification
In the context of national survey design there is always a concern that the sample respondents may be more or less representative of the population across different key demographics e.g. it’s unlikely we would put much faith in the survey’s accuracy if it had 90% male respondents on a question about the lived experience of women. Given that we can know before hand that certain demographic splits are not relective of the census data, we can use this information to appropriately re-weight the regressions fit to non-representative survey data.
We’ll demonstrate the idea of multi-level regression and post-stratification adjustment by replicating some of the steps discussed in Martin, Philips and Gelman’s “Multilevel Regression and Poststratification Case Studies”.
They cite data from the Cooperative Congressional Election Study (Schaffner, Ansolabehere, and Luks (2018)), a US nationwide survey designed by a consortium of 60 research teams and administered by YouGov. The outcome of interest is a binary question: Should employers decline coverage of abortions in insurance plans?
cces_all_df = pd.read_csv("data/mr_p_cces18_common_vv.csv.gz", low_memory=False)
cces_all_df.head()| caseid | commonweight | commonpostweight | vvweight | vvweight_post | tookpost | CCEStake | birthyr | gender | educ | ... | CL_party | CL_2018gvm | CL_2018pep | CL_2018pvm | starttime | endtime | starttime_post | endtime_post | DMA | dmaname | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 123464282 | 0.940543 | 0.7936 | 0.740858 | 0.641412 | 2 | 1 | 1964 | 2 | 4 | ... | 11.0 | 1.0 | NaN | NaN | 04oct2018 02:47:10 | 09oct2018 04:16:31 | 11nov2018 00:41:13 | 11nov2018 01:21:53 | 512.0 | BALTIMORE |
| 1 | 170169205 | 0.769724 | 0.7388 | 0.425236 | 0.415134 | 2 | 1 | 1971 | 2 | 2 | ... | 13.0 | NaN | 6.0 | 2.0 | 02oct2018 06:55:22 | 02oct2018 07:32:51 | 12nov2018 00:49:50 | 12nov2018 01:08:43 | 531.0 | "TRI-CITIES |
| 2 | 175996005 | 1.491642 | 1.3105 | 1.700094 | 1.603264 | 2 | 1 | 1958 | 2 | 3 | ... | 13.0 | 5.0 | NaN | NaN | 07oct2018 00:48:23 | 07oct2018 01:38:41 | 12nov2018 21:49:41 | 12nov2018 22:19:28 | 564.0 | CHARLESTON-HUNTINGTON |
| 3 | 176818556 | 5.104709 | 4.6304 | 5.946729 | 5.658840 | 2 | 1 | 1946 | 2 | 6 | ... | 4.0 | 3.0 | NaN | 3.0 | 11oct2018 15:20:26 | 11oct2018 16:18:42 | 11nov2018 13:24:16 | 11nov2018 14:00:14 | 803.0 | LOS ANGELES |
| 4 | 202120533 | 0.466526 | 0.3745 | 0.412451 | 0.422327 | 2 | 1 | 1972 | 2 | 2 | ... | 3.0 | 5.0 | NaN | NaN | 08oct2018 02:31:28 | 08oct2018 03:03:48 | 15nov2018 01:04:16 | 15nov2018 01:57:21 | 529.0 | LOUISVILLE |
5 rows × 526 columns
Cleaning Census Data
To prepare the census data for modelling we need to break the demographic data into appropriate stratum. We will break out these groupings as along broad categories familiar to audiences of election coverage news. Even these steps amount to a significant choice where we use our knowledge of pertinent demographics to decide upon the key strata we wish to represent in our model, as we seek to better predict and understand the voting outcome.
states = [
"AL",
"AK",
"AZ",
"AR",
"CA",
"CO",
"CT",
"DE",
"FL",
"GA",
"HI",
"ID",
"IL",
"IN",
"IA",
"KS",
"KY",
"LA",
"ME",
"MD",
"MA",
"MI",
"MN",
"MS",
"MO",
"MT",
"NE",
"NV",
"NH",
"NJ",
"NM",
"NY",
"NC",
"ND",
"OH",
"OK",
"OR",
"PA",
"RI",
"SC",
"SD",
"TN",
"TX",
"UT",
"VT",
"VA",
"WA",
"WV",
"WI",
"WY",
]
numbers = list(range(1, 56, 1))
lkup_states = dict(zip(numbers, states))
lkup_states
ethnicity = [
"White",
"Black",
"Hispanic",
"Asian",
"Native American",
"Mixed",
"Other",
"Middle Eastern",
]
numbers = list(range(1, 9, 1))
lkup_ethnicity = dict(zip(numbers, ethnicity))
lkup_ethnicity
edu = ["No HS", "HS", "Some college", "Associates", "4-Year College", "Post-grad"]
numbers = list(range(1, 7, 1))
lkup_edu = dict(zip(numbers, edu))
def clean_df(df):
## 0 Oppose and 1 Support
df["abortion"] = np.abs(df["CC18_321d"] - 2)
df["state"] = df["inputstate"].map(lkup_states)
## dichotomous (coded as -0.5 Female, +0.5 Male)
df["male"] = np.abs(df["gender"] - 2) - 0.5
df["eth"] = df["race"].map(lkup_ethnicity)
df["eth"] = np.where(
df["eth"].isin(["Asian", "Other", "Middle Eastern", "Mixed", "Native American"]),
"Other",
df["eth"],
)
df["age"] = 2018 - df["birthyr"]
df["age"] = pd.cut(
df["age"].astype(int),
[0, 29, 39, 49, 59, 69, 120],
labels=["18-29", "30-39", "40-49", "50-59", "60-69", "70+"],
ordered=True,
)
df["edu"] = df["educ"].map(lkup_edu)
df["edu"] = np.where(df["edu"].isin(["Some college", "Associates"]), "Some college", df["edu"])
df = df[["abortion", "state", "eth", "male", "age", "edu", "caseid"]]
return df.dropna()
statelevel_predictors_df = pd.read_csv("data/mr_p_statelevel_predictors.csv")
cces_all_df = clean_df(cces_all_df)
cces_all_df.head()| abortion | state | eth | male | age | edu | caseid | |
|---|---|---|---|---|---|---|---|
| 0 | 1.0 | MS | Other | -0.5 | 50-59 | Some college | 123464282 |
| 1 | 1.0 | WA | White | -0.5 | 40-49 | HS | 170169205 |
| 2 | 1.0 | RI | White | -0.5 | 60-69 | Some college | 175996005 |
| 3 | 0.0 | CO | Other | -0.5 | 70+ | Post-grad | 176818556 |
| 4 | 1.0 | MA | White | -0.5 | 40-49 | HS | 202120533 |
We will now show how estimates drawn from sample data (biased for whatever reasons of chance and circumstance) can be improved by using a post-stratification adjustment based on known facts about the size of the population in each strata considered in the model. This additional step is simply another modelling choice - another way to invest our model with information. In this manner the technique comes naturally in the Bayesian perspective.
Biased Sample
Consider a deliberately biased sample. Biased away from the census data and in this manner we show how to better recover population level estimates by incorporating details about the census population size across each of the stratum.
cces_df = cces_all_df.merge(statelevel_predictors_df, left_on="state", right_on="state", how="left")
cces_df["weight"] = (
5 * cces_df["repvote"]
+ (cces_df["age"] == "18-29") * 0.5
+ (cces_df["age"] == "30-39") * 1
+ (cces_df["age"] == "40-49") * 2
+ (cces_df["age"] == "50-59") * 4
+ (cces_df["age"] == "60-69") * 6
+ (cces_df["age"] == "70+") * 8
+ (cces_df["male"] == 1) * 20
+ (cces_df["eth"] == "White") * 1.05
)
cces_df = cces_df.sample(5000, weights="weight", random_state=1000)
cces_df.head()| abortion | state | eth | male | age | edu | caseid | repvote | region | weight | |
|---|---|---|---|---|---|---|---|---|---|---|
| 35171 | 0.0 | KY | White | -0.5 | 60-69 | HS | 415208636 | 0.656706 | South | 10.333531 |
| 5167 | 0.0 | NM | White | 0.5 | 60-69 | No HS | 412278020 | 0.453492 | West | 9.317460 |
| 52365 | 0.0 | OK | Hispanic | -0.5 | 30-39 | 4-Year College | 419467449 | 0.693047 | South | 4.465237 |
| 23762 | 1.0 | WV | White | -0.5 | 50-59 | Post-grad | 413757903 | 0.721611 | South | 8.658053 |
| 48197 | 0.0 | RI | White | 0.5 | 50-59 | 4-Year College | 417619385 | 0.416893 | Northeast | 7.134465 |
Visualise the Bias
Now we plot the outcome of expected shares within each demographic bucket across both the biased sample and the census data.
mosaic = """
ABCD
EEEE
"""
fig = plt.figure(layout="constrained", figsize=(20, 10))
ax_dict = fig.subplot_mosaic(mosaic)
def plot_var(var, ax):
a = (
cces_df.groupby(var, observed=False)[["abortion"]]
.mean()
.rename({"abortion": "share"}, axis=1)
.reset_index()
)
b = (
cces_all_df.groupby(var, observed=False)[["abortion"]]
.mean()
.rename({"abortion": "share_census"}, axis=1)
.reset_index()
)
a = a.merge(b).sort_values("share")
ax_dict[ax].vlines(a[var], a.share, a.share_census)
ax_dict[ax].scatter(a[var], a.share, color="blue", label="Sample")
ax_dict[ax].scatter(a[var], a.share_census, color="red", label="Census")
ax_dict[ax].set_ylabel("Proportion")
plot_var("age", "A")
plot_var("edu", "B")
plot_var("male", "C")
plot_var("eth", "D")
plot_var("state", "E")
ax_dict["E"].legend()
ax_dict["C"].set_xticklabels([])
ax_dict["C"].set_xlabel("Female / Male")
plt.suptitle("Comparison of Proportions: Survey Sample V Census", fontsize=20);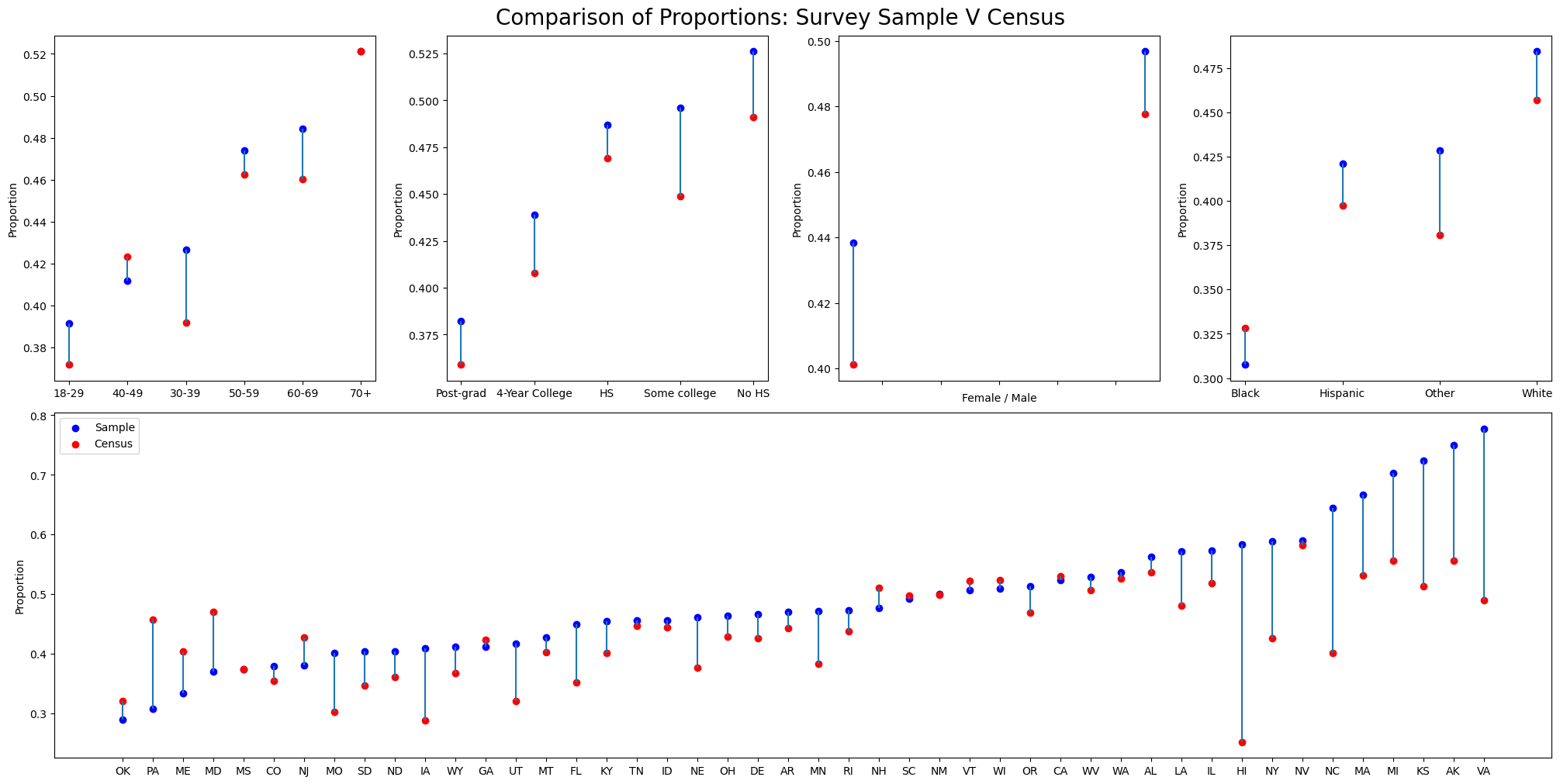
We can see here how the proportions differ markedly across the census report and our biased sample in how they represent the preferential votes with each strata. We now try and quantify the overall differences between the biased sample and the census report. We calculate the expected proportions in each dataset and their standard error.
def get_se_bernoulli(p, n):
return np.sqrt(p * (1 - p) / n)
sample_cces_estimate = {
"mean": np.mean(cces_df["abortion"].astype(float)),
"se": get_se_bernoulli(np.mean(cces_df["abortion"].astype(float)), len(cces_df)),
}
sample_cces_estimate
sample_cces_all_estimate = {
"mean": np.mean(cces_all_df["abortion"].astype(float)),
"se": get_se_bernoulli(np.mean(cces_all_df["abortion"].astype(float)), len(cces_all_df)),
}
sample_cces_all_estimate
summary = pd.DataFrame([sample_cces_all_estimate, sample_cces_estimate])
summary["data"] = ["Full Data", "Biased Data"]
summary| mean | se | data | |
|---|---|---|---|
| 0 | 0.434051 | 0.002113 | Full Data |
| 1 | 0.465000 | 0.007054 | Biased Data |
A 3 percent difference in a national survey is a substantial error in the case where the difference is due to preventable bias.
Modelling the Data
To facilitate regression based stratification we first need a regression model. In our case we will ultimately fit a multi-level regression model with intercept terms for each for each of the groups in our demographic stratum. In this way we try to account for the appropriate set of variables (as in the example above) to better specify the effect modification due to membership within a particular demographic stratum.
We will fit the model using bambi using the binomial link function on the biased sample data. But first we aggregate up by demographic strata and count the occurences within each strata.
model_df = (
cces_df.groupby(["state", "eth", "male", "age", "edu"], observed=False)
.agg({"caseid": "nunique", "abortion": "sum"})
.reset_index()
.sort_values("abortion", ascending=False)
.rename({"caseid": "n"}, axis=1)
.merge(statelevel_predictors_df, left_on="state", right_on="state", how="left")
)
model_df["abortion"] = model_df["abortion"].astype(int)
model_df["n"] = model_df["n"].astype(int)
model_df.head()| state | eth | male | age | edu | n | abortion | repvote | region | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | ID | White | -0.5 | 70+ | HS | 32 | 18 | 0.683102 | West |
| 1 | ID | White | 0.5 | 70+ | 4-Year College | 20 | 16 | 0.683102 | West |
| 2 | WV | White | 0.5 | 70+ | Some college | 17 | 13 | 0.721611 | South |
| 3 | WV | White | 0.5 | 70+ | 4-Year College | 15 | 12 | 0.721611 | South |
| 4 | ID | White | 0.5 | 70+ | Post-grad | 17 | 11 | 0.683102 | West |
Our model_df now has one row per Strata across all the demographic cuts.
Fit Base Model to Biased Sample
Here we use some of bambi’s latest functionality to assess the interaction effects between the variables.
formula = "p(abortion, n) ~ C(state) + C(eth) + C(edu) + male + repvote"
base_model = bmb.Model(formula, model_df, family="binomial")
result = base_model.fit(
random_seed=100,
target_accept=0.95,
inference_method="nutpie",
num_chains=4,
)We plot the predicted outcomes within each group using the plot_predictions function.
mosaic = """
AABB
CCCC
"""
fig = plt.figure(figsize=(20, 7))
axs = fig.subplot_mosaic(mosaic)
fig.suptitle("Plot Prediction per Class", fontsize=20)
p1 = bmb.interpret.plot_predictions(base_model, result, "eth")
p2 = bmb.interpret.plot_predictions(base_model, result, "edu")
p3 = bmb.interpret.plot_predictions(base_model, result, "state")
p1.on(axs["A"]).plot()
p2.on(axs["B"]).plot()
p3.on(axs["C"]).plot().show()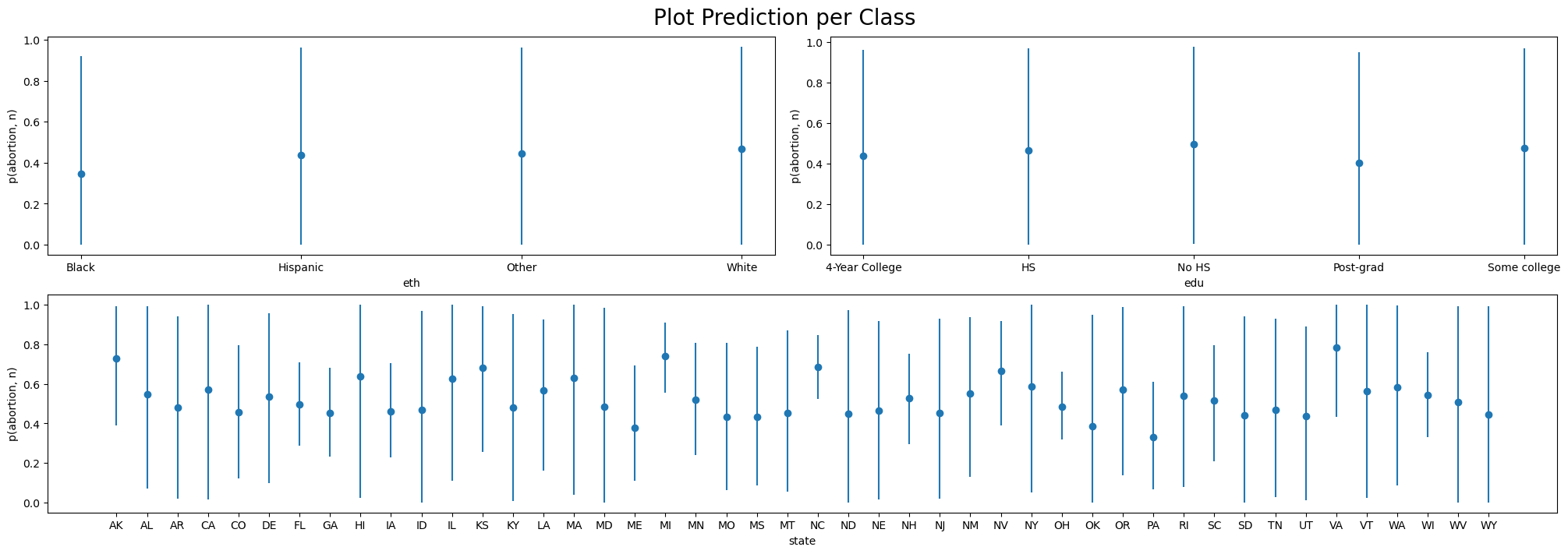
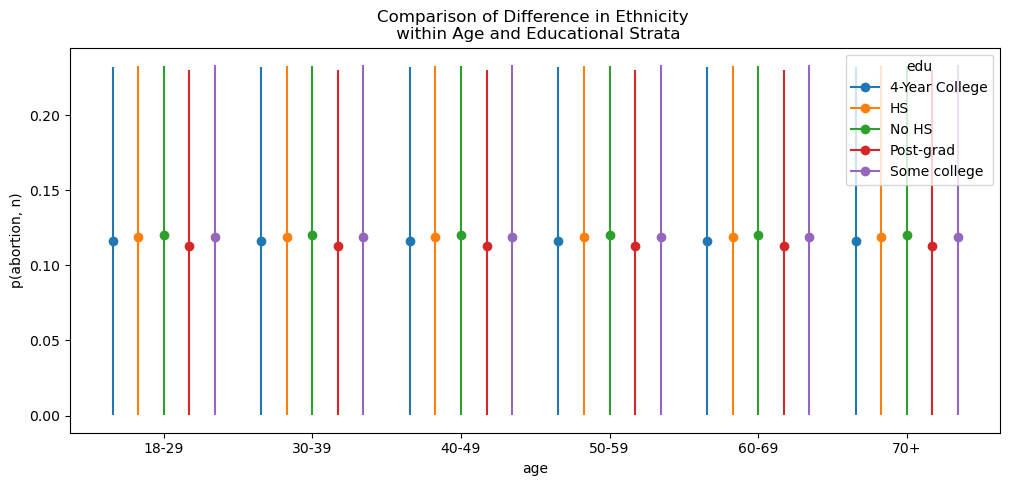
More interesting we can use the comparison functionality to compare differences in eth conditional on age and edu. Where we can see that the differences between ethnicities are pretty stable across all age groups, slightly shifted by within the Post-grad level of education.
bmb.interpret.plot_comparisons(
model=base_model,
idata=result,
contrast={"eth": ["Black", "White"]},
conditional=["age", "edu"],
comparison="diff",
subplot_kwargs={"main": "age", "group": "edu"},
fig_kwargs={
"title": "Comparison of Difference in Ethnicity \n within Age and Educational Strata",
"theme": {"figure.figsize": (12, 5)}
},
)
We can pull these specific estimates out into a table for closer inspection to see that the differences in response expected between the extremes of educational attainment are moderated by state iand race.
res = bmb.interpret.comparisons(
model=base_model,
idata=result,
contrast={"edu": ["Post-grad", "No HS"]},
conditional={"eth": ["Black", "White"], "state": ["NY", "CA", "ID", "VA"]},
comparison="diff",
)
res.summary| term | estimate_type | eth | state | repvote | male | value | estimate | lower_3.0% | upper_97.0% | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | edu | diff | Black | NY | 0.530191 | 0.0 | Post-grad_vs_No HS | 0.146893 | 0.069635 | 0.221777 |
| 1 | edu | diff | Black | CA | 0.530191 | 0.0 | Post-grad_vs_No HS | 0.140624 | 0.062200 | 0.214432 |
| 2 | edu | diff | Black | ID | 0.530191 | 0.0 | Post-grad_vs_No HS | 0.142420 | 0.066746 | 0.213304 |
| 3 | edu | diff | Black | VA | 0.530191 | 0.0 | Post-grad_vs_No HS | 0.156700 | 0.073555 | 0.229447 |
| 4 | edu | diff | White | NY | 0.530191 | 0.0 | Post-grad_vs_No HS | 0.164869 | 0.090354 | 0.238338 |
| 5 | edu | diff | White | CA | 0.530191 | 0.0 | Post-grad_vs_No HS | 0.164195 | 0.094848 | 0.244151 |
| 6 | edu | diff | White | ID | 0.530191 | 0.0 | Post-grad_vs_No HS | 0.167648 | 0.096155 | 0.246767 |
| 7 | edu | diff | White | VA | 0.530191 | 0.0 | Post-grad_vs_No HS | 0.138047 | 0.059941 | 0.219729 |
With this in mind we want to fit our final model to incorporate the variation we see here across the different levels of our stratified data.
Fit Final Model to Biased Sample
We can specify these features of our model using a hierarchical structure as follows:
\[ Pr(y_i = 1) = \text{logit}^{-1}( \alpha_{\rm s[i]}^{\rm state} + \alpha_{\rm a[i]}^{\rm age} + \alpha_{\rm r[i]}^{\rm eth} + \alpha_{\rm e[i]}^{\rm edu} + \beta^{\rm male} \cdot {\rm Male}_{\rm i} + \alpha_{\rm g[i], r[i]}^{\rm male.eth} + \alpha_{\rm e[i], a[i]}^{\rm edu.age} + \alpha_{\rm e[i], r[i]}^{\rm edu.eth} ) \]
Here we have used the fact that we can add components to the \(\alpha\) intercept terms and interaction effects to express the stratum specific variation in the outcomes that we’ve seen in our exploratory work. Using the bambi formula syntax. We have:
formula = "p(abortion, n) ~ male + repvote + (1 | state) + (1 | eth) + (1 | edu) + (1 | male:eth) + (1 | edu:age) + (1 | edu:eth)"
model_hierarchical = bmb.Model(formula, model_df, family="binomial")
result = model_hierarchical.fit(
draws=2000,
random_seed=110,
target_accept=0.95,
inference_method="nutpie",
)resultarviz.InferenceData
-
<xarray.Dataset> Size: 8MB Dimensions: (chain: 4, draw: 2000, state__factor_dim: 46, eth__factor_dim: 4, edu__factor_dim: 5, male:eth__factor_dim: 8, edu:age__factor_dim: 30, edu:eth__factor_dim: 20) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 16kB 0 1 2 3 4 ... 1996 1997 1998 1999 * state__factor_dim (state__factor_dim) object 368B 'AK' 'AL' ... 'WY' * eth__factor_dim (eth__factor_dim) object 32B 'Black' ... 'White' * edu__factor_dim (edu__factor_dim) object 40B '4-Year College' ...... * male:eth__factor_dim (male:eth__factor_dim) object 64B '-0.5:Black' ..... * edu:age__factor_dim (edu:age__factor_dim) object 240B '4-Year College... * edu:eth__factor_dim (edu:eth__factor_dim) object 160B '4-Year College... Data variables: (12/21) Intercept (chain, draw) float64 64kB 0.1293 0.2615 ... 0.742 male (chain, draw) float64 64kB 0.24 0.2765 ... 0.1366 repvote (chain, draw) float64 64kB -1.262 -1.248 ... -0.9758 1|state_sigma_log__ (chain, draw) float64 64kB -1.263 -1.1 ... -1.598 1|eth_sigma_log__ (chain, draw) float64 64kB -0.4397 ... -0.1616 1|edu_sigma_log__ (chain, draw) float64 64kB -0.3573 -0.204 ... -1.338 ... ... 1|state (chain, draw, state__factor_dim) float64 3MB -0.2... 1|eth (chain, draw, eth__factor_dim) float64 256kB -0.4... 1|edu (chain, draw, edu__factor_dim) float64 320kB 0.28... 1|male:eth (chain, draw, male:eth__factor_dim) float64 512kB ... 1|edu:age (chain, draw, edu:age__factor_dim) float64 2MB 0.... 1|edu:eth (chain, draw, edu:eth__factor_dim) float64 1MB 0.... Attributes: created_at: 2026-02-18T20:47:50.252058+00:00 arviz_version: 0.22.0 inference_library: nutpie inference_library_version: 0.15.2 sampling_time: 83.6549289226532 tuning_steps: 1000 modeling_interface: bambi modeling_interface_version: 0.16.1.dev42+g0d5870261.d20260218 -
<xarray.Dataset> Size: 672kB Dimensions: (chain: 4, draw: 2000) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 16kB 0 1 2 3 4 ... 1996 1997 1998 1999 Data variables: depth (chain, draw) uint64 64kB 5 6 6 6 5 6 ... 7 6 6 6 6 6 maxdepth_reached (chain, draw) bool 8kB False False ... False False index_in_trajectory (chain, draw) int64 64kB 18 28 -48 31 ... 51 29 -58 logp (chain, draw) float64 64kB -2.169e+03 ... -2.189e+03 energy (chain, draw) float64 64kB 2.232e+03 ... 2.252e+03 diverging (chain, draw) bool 8kB False False ... False False energy_error (chain, draw) float64 64kB 0.03601 -0.1001 ... 0.1007 step_size (chain, draw) float64 64kB 0.1042 0.1042 ... 0.08622 step_size_bar (chain, draw) float64 64kB 0.1042 0.1042 ... 0.08622 mean_tree_accept (chain, draw) float64 64kB 0.8713 0.9592 ... 0.9826 mean_tree_accept_sym (chain, draw) float64 64kB 0.9225 0.9499 ... 0.9495 n_steps (chain, draw) uint64 64kB 31 63 63 127 ... 63 63 63 63 Attributes: created_at: 2026-02-18T20:47:50.246104+00:00 arviz_version: 0.22.0 modeling_interface: bambi modeling_interface_version: 0.16.1.dev42+g0d5870261.d20260218 -
<xarray.Dataset> Size: 177kB Dimensions: (__obs__: 11040) Coordinates: * __obs__ (__obs__) int64 88kB 0 1 2 3 4 ... 11036 11037 11038 11039 Data variables: p(abortion, n) (__obs__) int64 88kB 18 16 13 12 11 11 11 ... 0 0 0 0 0 0 0 Attributes: created_at: 2026-02-18T20:47:50.251623+00:00 arviz_version: 0.22.0 inference_library: pymc inference_library_version: 5.27.1 modeling_interface: bambi modeling_interface_version: 0.16.1.dev42+g0d5870261.d20260218 -
<xarray.Dataset> Size: 8MB Dimensions: (chain: 4, draw: 1000, state__factor_dim: 46, eth__factor_dim: 4, edu__factor_dim: 5, male:eth__factor_dim: 8, edu:age__factor_dim: 30, edu:eth__factor_dim: 20) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 ... 995 996 997 998 999 * state__factor_dim (state__factor_dim) object 368B 'AK' 'AL' ... 'WY' * eth__factor_dim (eth__factor_dim) object 32B 'Black' ... 'White' * edu__factor_dim (edu__factor_dim) object 40B '4-Year College' ...... * male:eth__factor_dim (male:eth__factor_dim) object 64B '-0.5:Black' ..... * edu:age__factor_dim (edu:age__factor_dim) object 240B '4-Year College... * edu:eth__factor_dim (edu:eth__factor_dim) object 160B '4-Year College... Data variables: (12/27) Intercept (chain, draw) float64 32kB 0.7745 0.7745 ... -0.4028 male (chain, draw) float64 32kB 0.007282 ... -0.1249 repvote (chain, draw) float64 32kB -0.7152 ... -0.6112 1|state_sigma_log__ (chain, draw) float64 32kB 2.195 2.195 ... -1.463 1|state_offset (chain, draw, state__factor_dim) float64 1MB -0.8... 1|eth_sigma_log__ (chain, draw) float64 32kB 1.471 1.471 ... -1.009 ... ... 1|state (chain, draw, state__factor_dim) float64 1MB -7.4... 1|eth (chain, draw, eth__factor_dim) float64 128kB 2.67... 1|edu (chain, draw, edu__factor_dim) float64 160kB 0.59... 1|male:eth (chain, draw, male:eth__factor_dim) float64 256kB ... 1|edu:age (chain, draw, edu:age__factor_dim) float64 960kB ... 1|edu:eth (chain, draw, edu:eth__factor_dim) float64 640kB ... Attributes: created_at: 2026-02-18T20:47:50.236083+00:00 arviz_version: 0.22.0 modeling_interface: bambi modeling_interface_version: 0.16.1.dev42+g0d5870261.d20260218 -
<xarray.Dataset> Size: 336kB Dimensions: (chain: 4, draw: 1000) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 ... 995 996 997 998 999 Data variables: depth (chain, draw) uint64 32kB 3 0 3 1 0 4 ... 5 5 6 5 5 5 maxdepth_reached (chain, draw) bool 4kB False False ... False False index_in_trajectory (chain, draw) int64 32kB -4 0 -4 0 0 ... -20 12 -13 24 logp (chain, draw) float64 32kB -1.632e+04 ... -2.185e+03 energy (chain, draw) float64 32kB 2.083e+04 ... 2.23e+03 diverging (chain, draw) bool 4kB False True ... False False energy_error (chain, draw) float64 32kB -24.94 0.0 ... 0.03262 step_size (chain, draw) float64 32kB 1.095 0.1199 ... 0.08622 step_size_bar (chain, draw) float64 32kB 1.095 0.2939 ... 0.08622 mean_tree_accept (chain, draw) float64 32kB 1.0 0.0 ... 0.989 0.9603 mean_tree_accept_sym (chain, draw) float64 32kB 0.09493 0.0 ... 0.9745 n_steps (chain, draw) uint64 32kB 7 1 7 2 1 ... 63 63 31 31 31 Attributes: created_at: 2026-02-18T20:47:50.249069+00:00 arviz_version: 0.22.0 modeling_interface: bambi modeling_interface_version: 0.16.1.dev42+g0d5870261.d20260218
az.summary(result, var_names=["Intercept", "male", "1|edu", "1|eth", "repvote"])| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| Intercept | 0.402 | 0.464 | -0.501 | 1.251 | 0.014 | 0.014 | 1146.0 | 1307.0 | 1.00 |
| male | 0.217 | 0.183 | -0.141 | 0.566 | 0.004 | 0.008 | 2478.0 | 1931.0 | 1.00 |
| 1|edu[4-Year College] | -0.051 | 0.189 | -0.436 | 0.302 | 0.004 | 0.005 | 2964.0 | 3153.0 | 1.00 |
| 1|edu[HS] | 0.051 | 0.188 | -0.286 | 0.423 | 0.004 | 0.006 | 2572.0 | 3114.0 | 1.00 |
| 1|edu[No HS] | 0.153 | 0.215 | -0.187 | 0.600 | 0.004 | 0.005 | 2524.0 | 3865.0 | 1.00 |
| 1|edu[Post-grad] | -0.203 | 0.225 | -0.640 | 0.141 | 0.005 | 0.005 | 2091.0 | 2887.0 | 1.00 |
| 1|edu[Some college] | 0.023 | 0.187 | -0.327 | 0.393 | 0.004 | 0.005 | 2236.0 | 2991.0 | 1.00 |
| 1|eth[Black] | -0.400 | 0.384 | -1.112 | 0.269 | 0.013 | 0.014 | 870.0 | 1209.0 | 1.01 |
| 1|eth[Hispanic] | 0.076 | 0.349 | -0.604 | 0.723 | 0.011 | 0.015 | 1043.0 | 983.0 | 1.00 |
| 1|eth[Other] | 0.077 | 0.346 | -0.537 | 0.797 | 0.011 | 0.014 | 1104.0 | 1126.0 | 1.00 |
| 1|eth[White] | 0.169 | 0.354 | -0.444 | 0.896 | 0.013 | 0.016 | 816.0 | 829.0 | 1.01 |
| repvote | -1.179 | 0.525 | -2.151 | -0.176 | 0.008 | 0.006 | 4712.0 | 5203.0 | 1.00 |
The terms in the model formula allow for specific intercept terms across the demographic splits of eth, edu, and state. These represent stratum specific adjustments of the intercept term in the model. Similarly we invoke intercepts for the interaction terms of age:edu, male:eth and edu:eth. Each of these cohorts represents a share of the data in our sample.
model_hierarchical.graph()
We then predict the outcomes implied by the biased sample. These predictions are to be adjusted by what we take to be the share of that demographic cohort in population. We can plot the posterior predictive distribution against the observed data from our biased sample to see that we have generally good fit to the distribution.
model_hierarchical.predict(result, kind="response")
ax = az.plot_ppc(result, figsize=(8, 5), kind="cumulative", observed_rug=True, num_pp_samples=500)
ax.set_title("Posterior Predictive Checks \n On Biased Sample");/home/tomas/Desktop/oss/bambinos/bambi/.pixi/envs/dev/lib/python3.13/site-packages/IPython/core/events.py:82: UserWarning: Creating legend with loc="best" can be slow with large amounts of data.
func(*args, **kwargs)
/home/tomas/Desktop/oss/bambinos/bambi/.pixi/envs/dev/lib/python3.13/site-packages/IPython/core/pylabtools.py:170: UserWarning: Creating legend with loc="best" can be slow with large amounts of data.
fig.canvas.print_figure(bytes_io, **kw)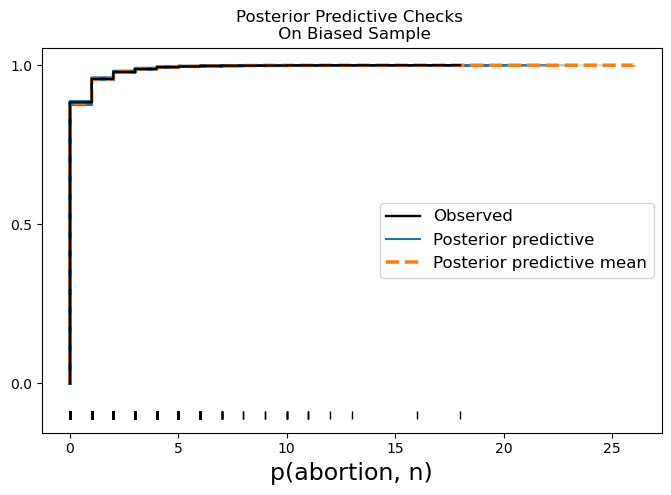
Apply the Post-stratification Weighting
We now use the fitted model to predict the voting shares on the data where we use the genuine state numbers per strata. To do so we load data from the national census and augment our data set so as to be able to apply the appropriate weights.
poststrat_df = pd.read_csv("data/mr_p_poststrat_df.csv")
new_data = poststrat_df.merge(
statelevel_predictors_df, left_on="state", right_on="state", how="left"
)
new_data.rename({"educ": "edu"}, axis=1, inplace=True)
new_data = model_df.merge(
new_data,
how="left",
left_on=["state", "eth", "male", "age", "edu"],
right_on=["state", "eth", "male", "age", "edu"],
).rename({"n_y": "n", "repvote_y": "repvote"}, axis=1)[
["state", "eth", "male", "age", "edu", "n", "repvote"]
]
new_data = new_data.merge(
new_data.groupby("state").agg({"n": "sum"}).reset_index().rename({"n": "state_total"}, axis=1)
)
new_data["state_percent"] = new_data["n"] / new_data["state_total"]
new_data.head()| state | eth | male | age | edu | n | repvote | state_total | state_percent | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | ID | White | -0.5 | 70+ | HS | 31503 | 0.683102 | 1193885 | 0.026387 |
| 1 | ID | White | 0.5 | 70+ | 4-Year College | 11809 | 0.683102 | 1193885 | 0.009891 |
| 2 | WV | White | 0.5 | 70+ | Some college | 17089 | 0.721611 | 1441882 | 0.011852 |
| 3 | WV | White | 0.5 | 70+ | 4-Year College | 7396 | 0.721611 | 1441882 | 0.005129 |
| 4 | ID | White | 0.5 | 70+ | Post-grad | 9873 | 0.683102 | 1193885 | 0.008270 |
This dataset is exactly the same structure and length as our input data to the fitted model. We have simply switched the observed counts across the demographic strata with the counts that reflect their proportion in the national survey. Additionally we have calculated the state totals and the share of each strata within the state. This will be important for later when we use this state_percent variable to calculate an adjusted MrP estimate of the predictions at a state level. We now use this data set with our fitted model to generate posterior predictive distribution.
result_adjust = model_hierarchical.predict(result, data=new_data, inplace=False, kind="response")
result_adjustarviz.InferenceData
-
<xarray.Dataset> Size: 715MB Dimensions: (chain: 4, draw: 2000, state__factor_dim: 46, eth__factor_dim: 4, edu__factor_dim: 5, male:eth__factor_dim: 8, edu:age__factor_dim: 30, edu:eth__factor_dim: 20, __obs__: 11040) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 16kB 0 1 2 3 4 ... 1996 1997 1998 1999 * state__factor_dim (state__factor_dim) object 368B 'AK' 'AL' ... 'WY' * eth__factor_dim (eth__factor_dim) object 32B 'Black' ... 'White' * edu__factor_dim (edu__factor_dim) object 40B '4-Year College' ...... * male:eth__factor_dim (male:eth__factor_dim) object 64B '-0.5:Black' ..... * edu:age__factor_dim (edu:age__factor_dim) object 240B '4-Year College... * edu:eth__factor_dim (edu:eth__factor_dim) object 160B '4-Year College... * __obs__ (__obs__) int64 88kB 0 1 2 3 ... 11037 11038 11039 Data variables: (12/22) Intercept (chain, draw) float64 64kB 0.1293 0.2615 ... 0.742 male (chain, draw) float64 64kB 0.24 0.2765 ... 0.1366 repvote (chain, draw) float64 64kB -1.262 -1.248 ... -0.9758 1|state_sigma_log__ (chain, draw) float64 64kB -1.263 -1.1 ... -1.598 1|eth_sigma_log__ (chain, draw) float64 64kB -0.4397 ... -0.1616 1|edu_sigma_log__ (chain, draw) float64 64kB -0.3573 -0.204 ... -1.338 ... ... 1|eth (chain, draw, eth__factor_dim) float64 256kB -0.4... 1|edu (chain, draw, edu__factor_dim) float64 320kB 0.28... 1|male:eth (chain, draw, male:eth__factor_dim) float64 512kB ... 1|edu:age (chain, draw, edu:age__factor_dim) float64 2MB 0.... 1|edu:eth (chain, draw, edu:eth__factor_dim) float64 1MB 0.... p (chain, draw, __obs__) float64 707MB 0.4905 ... 0... Attributes: created_at: 2026-02-18T20:47:50.252058+00:00 arviz_version: 0.22.0 inference_library: nutpie inference_library_version: 0.15.2 sampling_time: 83.6549289226532 tuning_steps: 1000 modeling_interface: bambi modeling_interface_version: 0.16.1.dev42+g0d5870261.d20260218 -
<xarray.Dataset> Size: 707MB Dimensions: (chain: 4, draw: 2000, __obs__: 11040) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 16kB 0 1 2 3 4 5 ... 1995 1996 1997 1998 1999 * __obs__ (__obs__) int64 88kB 0 1 2 3 4 ... 11036 11037 11038 11039 Data variables: p(abortion, n) (chain, draw, __obs__) int64 707MB 15438 6759 ... 2018 1888 Attributes: modeling_interface: bambi modeling_interface_version: 0.16.1.dev42+g0d5870261.d20260218 -
<xarray.Dataset> Size: 672kB Dimensions: (chain: 4, draw: 2000) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 16kB 0 1 2 3 4 ... 1996 1997 1998 1999 Data variables: depth (chain, draw) uint64 64kB 5 6 6 6 5 6 ... 7 6 6 6 6 6 maxdepth_reached (chain, draw) bool 8kB False False ... False False index_in_trajectory (chain, draw) int64 64kB 18 28 -48 31 ... 51 29 -58 logp (chain, draw) float64 64kB -2.169e+03 ... -2.189e+03 energy (chain, draw) float64 64kB 2.232e+03 ... 2.252e+03 diverging (chain, draw) bool 8kB False False ... False False energy_error (chain, draw) float64 64kB 0.03601 -0.1001 ... 0.1007 step_size (chain, draw) float64 64kB 0.1042 0.1042 ... 0.08622 step_size_bar (chain, draw) float64 64kB 0.1042 0.1042 ... 0.08622 mean_tree_accept (chain, draw) float64 64kB 0.8713 0.9592 ... 0.9826 mean_tree_accept_sym (chain, draw) float64 64kB 0.9225 0.9499 ... 0.9495 n_steps (chain, draw) uint64 64kB 31 63 63 127 ... 63 63 63 63 Attributes: created_at: 2026-02-18T20:47:50.246104+00:00 arviz_version: 0.22.0 modeling_interface: bambi modeling_interface_version: 0.16.1.dev42+g0d5870261.d20260218 -
<xarray.Dataset> Size: 177kB Dimensions: (__obs__: 11040) Coordinates: * __obs__ (__obs__) int64 88kB 0 1 2 3 4 ... 11036 11037 11038 11039 Data variables: p(abortion, n) (__obs__) int64 88kB 18 16 13 12 11 11 11 ... 0 0 0 0 0 0 0 Attributes: created_at: 2026-02-18T20:47:50.251623+00:00 arviz_version: 0.22.0 inference_library: pymc inference_library_version: 5.27.1 modeling_interface: bambi modeling_interface_version: 0.16.1.dev42+g0d5870261.d20260218 -
<xarray.Dataset> Size: 8MB Dimensions: (chain: 4, draw: 1000, state__factor_dim: 46, eth__factor_dim: 4, edu__factor_dim: 5, male:eth__factor_dim: 8, edu:age__factor_dim: 30, edu:eth__factor_dim: 20) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 ... 995 996 997 998 999 * state__factor_dim (state__factor_dim) object 368B 'AK' 'AL' ... 'WY' * eth__factor_dim (eth__factor_dim) object 32B 'Black' ... 'White' * edu__factor_dim (edu__factor_dim) object 40B '4-Year College' ...... * male:eth__factor_dim (male:eth__factor_dim) object 64B '-0.5:Black' ..... * edu:age__factor_dim (edu:age__factor_dim) object 240B '4-Year College... * edu:eth__factor_dim (edu:eth__factor_dim) object 160B '4-Year College... Data variables: (12/27) Intercept (chain, draw) float64 32kB 0.7745 0.7745 ... -0.4028 male (chain, draw) float64 32kB 0.007282 ... -0.1249 repvote (chain, draw) float64 32kB -0.7152 ... -0.6112 1|state_sigma_log__ (chain, draw) float64 32kB 2.195 2.195 ... -1.463 1|state_offset (chain, draw, state__factor_dim) float64 1MB -0.8... 1|eth_sigma_log__ (chain, draw) float64 32kB 1.471 1.471 ... -1.009 ... ... 1|state (chain, draw, state__factor_dim) float64 1MB -7.4... 1|eth (chain, draw, eth__factor_dim) float64 128kB 2.67... 1|edu (chain, draw, edu__factor_dim) float64 160kB 0.59... 1|male:eth (chain, draw, male:eth__factor_dim) float64 256kB ... 1|edu:age (chain, draw, edu:age__factor_dim) float64 960kB ... 1|edu:eth (chain, draw, edu:eth__factor_dim) float64 640kB ... Attributes: created_at: 2026-02-18T20:47:50.236083+00:00 arviz_version: 0.22.0 modeling_interface: bambi modeling_interface_version: 0.16.1.dev42+g0d5870261.d20260218 -
<xarray.Dataset> Size: 336kB Dimensions: (chain: 4, draw: 1000) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 ... 995 996 997 998 999 Data variables: depth (chain, draw) uint64 32kB 3 0 3 1 0 4 ... 5 5 6 5 5 5 maxdepth_reached (chain, draw) bool 4kB False False ... False False index_in_trajectory (chain, draw) int64 32kB -4 0 -4 0 0 ... -20 12 -13 24 logp (chain, draw) float64 32kB -1.632e+04 ... -2.185e+03 energy (chain, draw) float64 32kB 2.083e+04 ... 2.23e+03 diverging (chain, draw) bool 4kB False True ... False False energy_error (chain, draw) float64 32kB -24.94 0.0 ... 0.03262 step_size (chain, draw) float64 32kB 1.095 0.1199 ... 0.08622 step_size_bar (chain, draw) float64 32kB 1.095 0.2939 ... 0.08622 mean_tree_accept (chain, draw) float64 32kB 1.0 0.0 ... 0.989 0.9603 mean_tree_accept_sym (chain, draw) float64 32kB 0.09493 0.0 ... 0.9745 n_steps (chain, draw) uint64 32kB 7 1 7 2 1 ... 63 63 31 31 31 Attributes: created_at: 2026-02-18T20:47:50.249069+00:00 arviz_version: 0.22.0 modeling_interface: bambi modeling_interface_version: 0.16.1.dev42+g0d5870261.d20260218
Make Adjustments by State
We need to adjust each state specific strata by the weight appropriate for each state to post-stratify the estimates.To do so we extract the indices for each strata in our data on a state by state basis. Then we weight the predicted estimate by the appropriate percentage on a state basis and sum them to recover a state level estimate.
estimates = []
abortion_posterior_base = az.extract(result, num_samples=2000)["p"]
abortion_posterior_mrp = az.extract(result_adjust, num_samples=2000)["p"]
for s in new_data["state"].unique():
idx = new_data.index[new_data["state"] == s].tolist()
predicted_mrp = (
((abortion_posterior_mrp[idx].mean(dim="sample") * new_data.iloc[idx]["state_percent"]))
.sum()
.item()
)
predicted_mrp_lb = (
(
(
abortion_posterior_mrp[idx].quantile(0.025, dim="sample")
* new_data.iloc[idx]["state_percent"]
)
)
.sum()
.item()
)
predicted_mrp_ub = (
(
(
abortion_posterior_mrp[idx].quantile(0.975, dim="sample")
* new_data.iloc[idx]["state_percent"]
)
)
.sum()
.item()
)
predicted = abortion_posterior_base[idx].mean().item()
base_lb = abortion_posterior_base[idx].quantile(0.025).item()
base_ub = abortion_posterior_base[idx].quantile(0.975).item()
estimates.append(
[s, predicted, base_lb, base_ub, predicted_mrp, predicted_mrp_ub, predicted_mrp_lb]
)
state_predicted = pd.DataFrame(
estimates,
columns=["state", "base_expected", "base_lb", "base_ub", "mrp_adjusted", "mrp_ub", "mrp_lb"],
)
state_predicted = (
state_predicted.merge(cces_all_df.groupby("state")[["abortion"]].mean().reset_index())
.sort_values("mrp_adjusted")
.rename({"abortion": "census_share"}, axis=1)
)
state_predicted.head()| state | base_expected | base_lb | base_ub | mrp_adjusted | mrp_ub | mrp_lb | census_share | |
|---|---|---|---|---|---|---|---|---|
| 7 | OK | 0.285873 | 0.132348 | 0.459846 | 0.325240 | 0.413190 | 0.244487 | 0.321553 |
| 37 | MS | 0.378689 | 0.186249 | 0.578959 | 0.379689 | 0.491720 | 0.276487 | 0.374640 |
| 2 | CO | 0.358461 | 0.178999 | 0.543424 | 0.396658 | 0.482802 | 0.313551 | 0.354857 |
| 29 | ME | 0.358675 | 0.166280 | 0.567506 | 0.418101 | 0.535924 | 0.304704 | 0.403636 |
| 24 | MO | 0.378204 | 0.185540 | 0.578580 | 0.419414 | 0.527868 | 0.316308 | 0.302954 |
This was the crucial step and we’ll need to unpack it a little. We have taken (state by state) each demographic strata and reweighted the expected posterior predictive value by the share that strata represents in the national census within that state. We have then aggregated this score within the state to generate a state specific value. This value can now be compared to the expected value derived from our biased data and, more interestingly, the value reported in the national census.
Plot the Effect of Adjustment
These adjusted estimates can be plotted against the shares ascribed at the state level in the census. These adjustments provide a far better reflection of the national picture than the ones derived from model fitted to the biased sample.
fig, axs = plt.subplots(2, 1, figsize=(17, 10))
axs = axs.flatten()
ax = axs[0]
ax1 = axs[1]
ax.scatter(
state_predicted["state"], state_predicted["base_expected"], color="red", label="Biased Sample"
)
ax.scatter(
state_predicted["state"],
state_predicted["mrp_adjusted"],
color="slateblue",
label="Mr P Adjusted",
)
ax.scatter(
state_predicted["state"],
state_predicted["census_share"],
color="darkgreen",
label="Census Aggregates",
)
ax.legend()
ax.vlines(
state_predicted["state"],
state_predicted["mrp_adjusted"],
state_predicted["census_share"],
color="black",
linestyles="--",
)
ax1.scatter(
state_predicted["state"], state_predicted["base_expected"], color="red", label="Biased Sample"
)
ax1.scatter(
state_predicted["state"],
state_predicted["mrp_adjusted"],
color="slateblue",
label="Mr P Adjusted",
)
ax1.legend()
ax1.vlines(
state_predicted["state"], state_predicted["base_ub"], state_predicted["base_lb"], color="red"
)
ax1.vlines(
state_predicted["state"],
state_predicted["mrp_ub"],
state_predicted["mrp_lb"],
color="slateblue",
)
ax.set_xlabel("State")
ax.set_ylabel("Proportion")
ax1.set_title(
"Comparison of Uncertainty in Biased Predictions and Post-stratified Adjustment", fontsize=15
)
ax.set_title("Comparison of Post-stratified Adjustment and Census Report", fontsize=15)
ax1.set_ylabel("Proportion");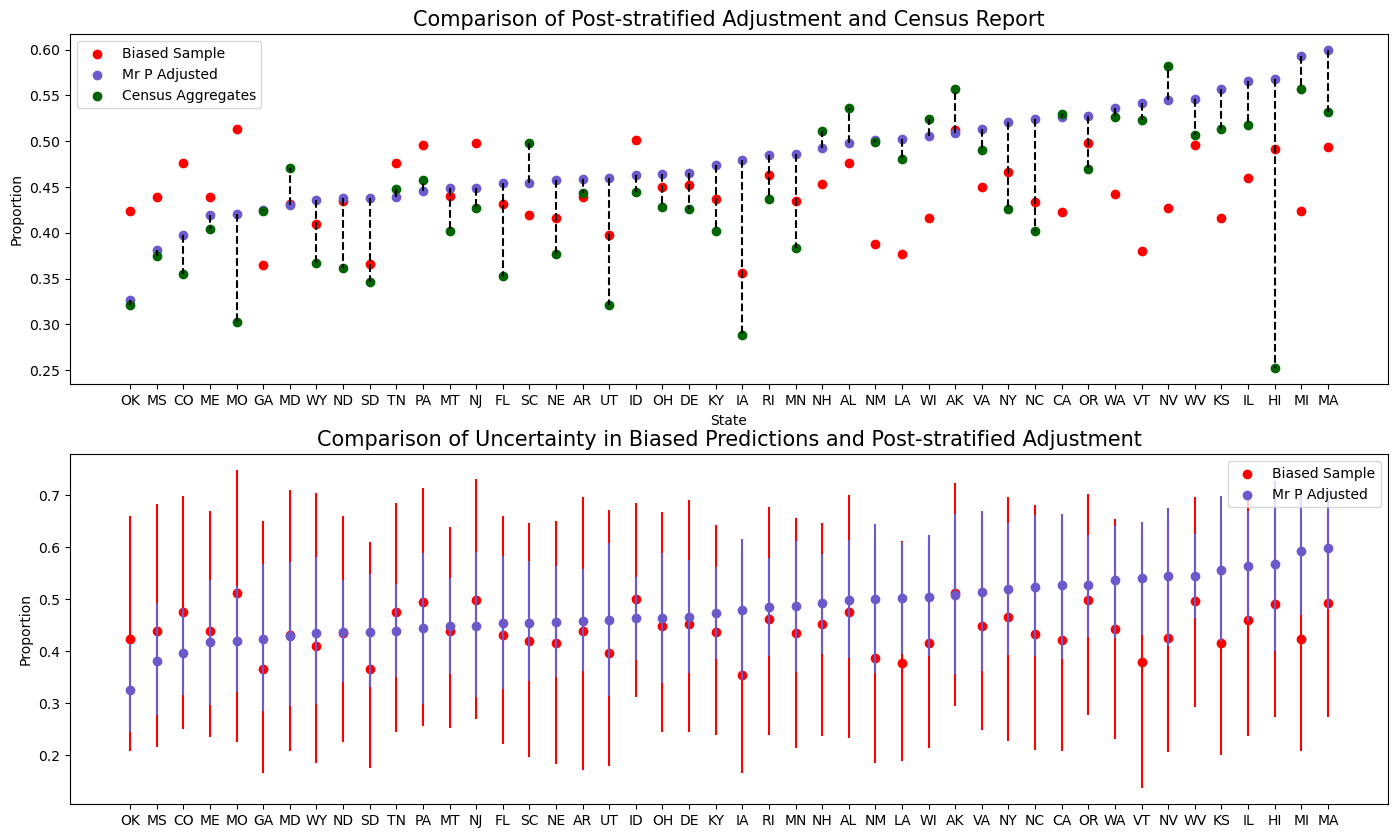
In the top plot here we see the state specific MrP estimates for the proportion voting yes, compared to the estimate inferred from the biased sample and estimates from the national census. We can see how the MrP estimates are much closer to those drawn from the national census.
In the below plot we’ve shown the estimates from the MrP model and the estimates drawn from the biased sample, but here we’ve shown the uncertainty in the estimation on a state level. Clearly, the MrP adjustments also shrinks the uncertainty in our estimate of vote-share.
MrP is in this sense a corrective procedure for the avoidance of bias in sample data, where we have strong evidence for adjusting the weight accorded to any stratum of data in our population.
Conclusion
In this notebook we have seen how to use bambi to concisely and quickly apply the technique of multilevel regression and post-stratification. We’ve seen how this technique is a natural and compelling extension to regression modelling in general, that incorporates prior knowledge in an interesting and flexible manner.
The problems of representation in data are serious. Policy gets made and changed on the basis of anticipated policy effects. Without the ability to control and adjust for non-representative samples, politicians and policy makers risk prioritising initiatives for a vocal majority among the represented in the sample. The question of whether a given sample is “good” or “bad” cannot (at the time) ever be known, so some care needs to be taken when choosing to adjust your model of the data.
Predictions made from sample data are consequential. It’s not even an exaggeration to say that the fates of entire nations can hang on decisions made from poorly understood sampling procedures. Multilevel regression and post-stratification is an apt tool for making the adjustments required and guiding decisions makers in crucial policy choices, but it should be used carefully.
%load_ext watermark
%watermark -n -u -v -w -p arviz,bambi,numpy,nutpie,pymc,pytensorLast updated: Wed Feb 18 2026
Python implementation: CPython
Python version : 3.13.9
IPython version : 9.6.0
arviz : 0.22.0
bambi : 0.16.1.dev42+g0d5870261.d20260218
numpy : 2.3.3
nutpie : 0.15.2
pymc : 5.27.1
pytensor: 2.37.0
Watermark: 2.5.0