import arviz as az
import bambi as bmb
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from scipy import stats
from scipy.special import expit
az.style.use("arviz-darkgrid")Beta Regression
This example has been contributed by Tyler James Burch (@tjburch on GitHub).
In this example, we’ll look at using the Beta distribution for regression models. The Beta distribution is a probability distribution bounded on the interval [0, 1], which makes it well-suited to model probabilities or proportions. In fact, in much of the Bayesian literature, the Beta distribution is introduced as a prior distribution for the probability \(p\) parameter of the Binomial distribution (in fact, it’s the conjugate prior for the Binomial distribution).
Simulated Beta Distribution
To start getting an intuitive sense of the Beta distribution, we’ll model coin flipping probabilities. Say we grab all the coins out of our pocket, we might have some fresh from the mint, but we might also have some old ones. Due to the variation, some may be slightly biased toward heads or tails, and our goal is to model distribution of the probabilities of flipping heads for the coins in our pocket.
Since we trust the mint, we’ll say the \(\alpha\) and \(\beta\) are both large, we’ll use 1,000 for each, which gives a distribution spanning from 0.45 to 0.55.
alpha = 1_000
beta = 1_000
p = np.random.beta(alpha, beta, size=10_000)
az.plot_kde(p)
plt.xlabel("$p$");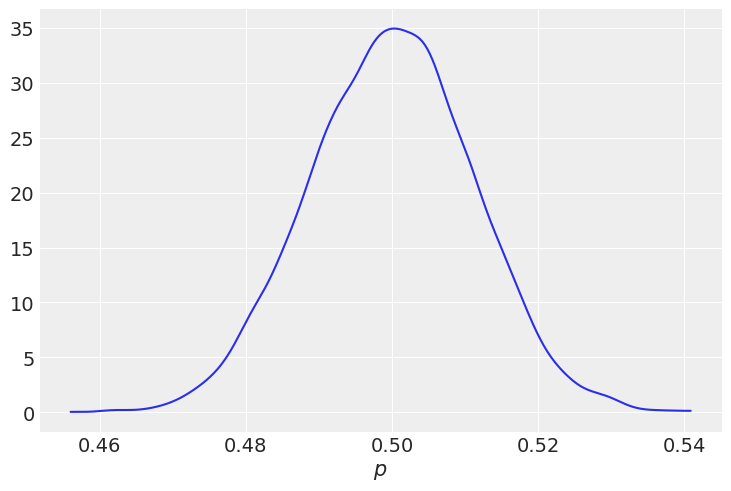
Next, we’ll use Bambi to try to recover the parameters of the Beta distribution. Since we have no predictors, we can do a intercept-only model to try to recover them.
data = pd.DataFrame({"probabilities": p})
model = bmb.Model("probabilities ~ 1", data, family="beta")
fitted = model.fit()Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [kappa, Intercept]/Users/hslu-n0006897/projects/bambi/.pixi/envs/dev/lib/python3.13/site-packages/pymc/step_methods/hmc/quadpotential.py:316: RuntimeWarning: overflow encountered in dot
return 0.5 * np.dot(x, v_out)Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 2 seconds.az.plot_trace(fitted);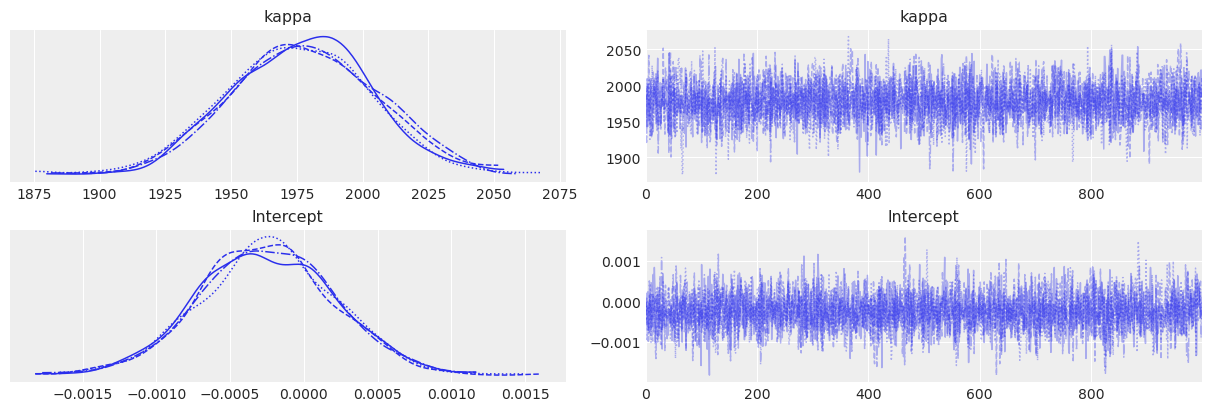
az.summary(fitted)| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| kappa | 2039.034 | 29.362 | 1984.97 | 2093.920 | 0.428 | 0.452 | 4715.0 | 3157.0 | 1.0 |
| Intercept | 0.000 | 0.000 | -0.00 | 0.001 | 0.000 | 0.000 | 4580.0 | 3234.0 | 1.0 |
The model fit, but clearly these parameters are not the ones that we used above. For Beta regression, we use a linear model for the mean, so we use the \(\mu\) and \(\sigma\) formulation. To link the two, we use
\[\alpha = \mu \kappa\]
\[\beta = (1-\mu)\kappa\]
and \(\kappa\) is a function of the mean and variance,
\[\kappa = \frac{\mu(1-\mu)}{\sigma^2} - 1\]
Rather than \(\sigma\), you’ll note Bambi returns \(\kappa\). We’ll define a function to retrieve our original parameters.
def mukappa_to_alphabeta(mu, kappa):
# Calculate alpha and beta
alpha = mu * kappa
beta = (1 - mu) * kappa
# Get mean values and 95% HDIs
alpha_mean = alpha.mean(("chain", "draw")).item()
alpha_hdi = az.hdi(alpha, hdi_prob=.95)["x"].values
beta_mean = beta.mean(("chain", "draw")).item()
beta_hdi = az.hdi(beta, hdi_prob=.95)["x"].values
return alpha_mean, alpha_hdi, beta_mean, beta_hdi
alpha, alpha_hdi, beta, beta_hdi = mukappa_to_alphabeta(
expit(fitted.posterior["Intercept"]),
fitted.posterior["kappa"]
)
print(f"Alpha - mean: {np.round(alpha)}, 95% HDI: {np.round(alpha_hdi[0])} - {np.round(alpha_hdi[1])}")
print(f"Beta - mean: {np.round(beta)}, 95% HDI: {np.round(beta_hdi[0])} - {np.round(beta_hdi[1])}")Alpha - mean: 1020.0, 95% HDI: 990.0 - 1047.0
Beta - mean: 1019.0, 95% HDI: 990.0 - 1047.0We’ve managed to recover our parameters with an intercept-only model.
Beta Regression with Predictors
Perhaps we have a little more information on the coins in our pocket. We notice that the coins have accumulated dirt on either side, which would shift the probability of getting a tails or heads. In reality, we would not know how much the dirt affects the probability distribution, we would like to recover that parameter. We’ll construct this toy example by saying that each micron of dirt shifts the \(\alpha\) parameter by 5.0. Further, the amount of dirt is distributed according to a Half Normal distribution with a standard deviation of 25 per side.
We’ll start by looking at the difference in probability for a coin with a lot of dirt on either side.
effect_per_micron = 5.0
# Clean Coin
alpha = 1_000
beta = 1_000
p = np.random.beta(alpha, beta, size=10_000)
# Add two std to tails side (heads more likely)
p_heads = np.random.beta(alpha + 50 * effect_per_micron, beta, size=10_000)
# Add two std to heads side (tails more likely)
p_tails = np.random.beta(alpha - 50 * effect_per_micron, beta, size=10_000)
az.plot_kde(p, label="Clean Coin")
az.plot_kde(p_heads, label="Biased toward heads", plot_kwargs={"color":"C1"})
az.plot_kde(p_tails, label="Biased toward tails", plot_kwargs={"color":"C2"})
plt.xlabel("$p$")
plt.ylim(top=plt.ylim()[1]*1.25);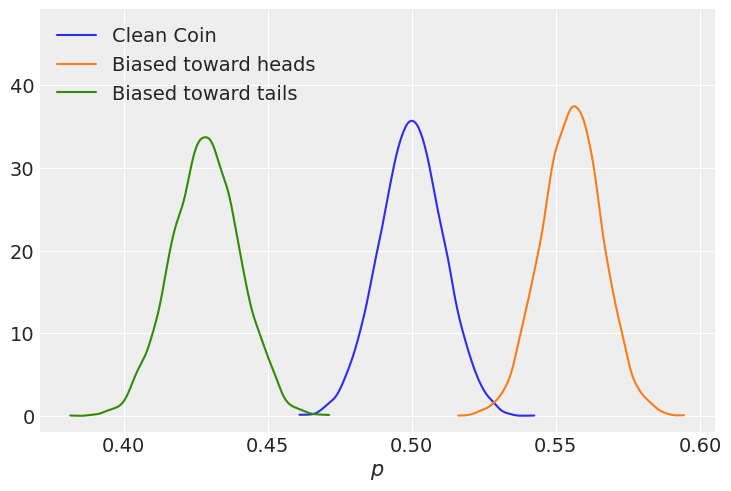
Next, we’ll generate a toy dataset according to our specifications above. As an added foil, we will also assume that we’re limited in our measuring equipment, that we can only measure correctly to the nearest integer micron.
# Create amount of dirt on top and bottom
heads_bias_dirt = stats.halfnorm(loc=0, scale=25).rvs(size=1_000)
tails_bias_dirt = stats.halfnorm(loc=0, scale=25).rvs(size=1_000)
# Create the probability per coin
alpha = np.repeat(1_000, 1_000)
alpha = alpha + effect_per_micron * heads_bias_dirt - effect_per_micron * tails_bias_dirt
beta = np.repeat(1_000, 1_000)
p = np.random.beta(alpha, beta)
df = pd.DataFrame({
"p" : p,
"heads_bias_dirt" : heads_bias_dirt.round(),
"tails_bias_dirt" : tails_bias_dirt.round()
})
df.head()| p | heads_bias_dirt | tails_bias_dirt | |
|---|---|---|---|
| 0 | 0.482361 | 18.0 | 32.0 |
| 1 | 0.536776 | 24.0 | 0.0 |
| 2 | 0.372461 | 1.0 | 81.0 |
| 3 | 0.498130 | 11.0 | 5.0 |
| 4 | 0.441909 | 7.0 | 56.0 |
Taking a look at our new dataset:
fig,ax = plt.subplots(1,3, figsize=(16,5))
df["p"].plot.kde(ax=ax[0])
ax[0].set_xlabel("$p$")
df["heads_bias_dirt"].plot.hist(ax=ax[1], bins=np.arange(0,df["heads_bias_dirt"].max()))
ax[1].set_xlabel("Measured Dirt Biasing Toward Heads ($\mu m$)")
df["tails_bias_dirt"].plot.hist(ax=ax[2], bins=np.arange(0,df["tails_bias_dirt"].max()))
ax[2].set_xlabel("Measured Dirt Biasing Toward Tails ($\mu m$)");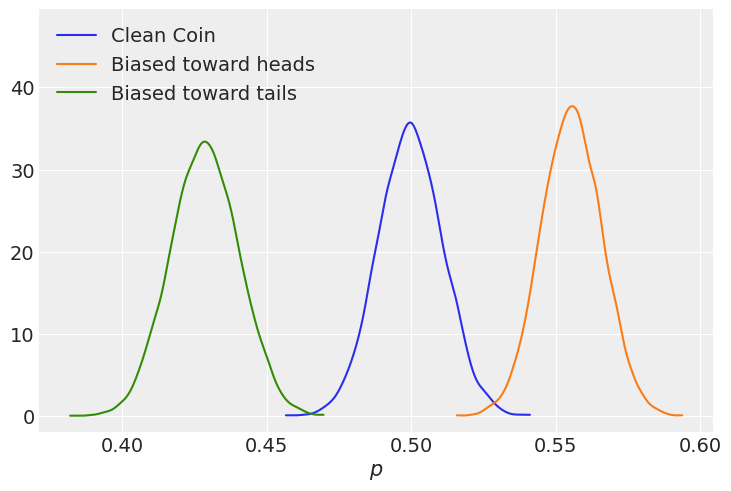
Next we want to make a model to recover the effect per micron of dirt per side. So far, we’ve considered the biasing toward one side or another independently. A linear model might look something like this:
\[ \begin{aligned} p &\sim \text{Beta}(\mu, \sigma) \\ \text{logit}(\mu) &= \text{ Normal}( \alpha + \beta_h d_h + \beta_t d_t) \end{aligned} \]
Where \(d_h\) and \(d_t\) are the measured dirt (in microns) biasing the probability toward heads and tails respectively, \(\beta_h\) and \(\beta_t\) are coefficients for how much a micron of dirt affects each independent side, and \(\alpha\) is the intercept. Also note the logit link function used here, since our outcome is on the scale of 0-1, it makes sense that the link must also put our mean on that scale. Logit is the default link function, however Bambi supports the identity, probit, and cloglog links as well.
In this toy example, we’ve constructed it such that dirt should not affect one side differently from another, so we can wrap those into one coefficient: \(\beta = \beta_h = -\beta_t\). This makes the last line of the model:
\[ \text{logit}(\mu) = \text{ Normal}( \alpha + \beta \Delta d) \]
where \(\Delta d = d_h - d_t\).
Putting that into our dataset, then constructing this model in Bambi,
df["delta_d"] = df["heads_bias_dirt"] - df["tails_bias_dirt"]
dirt_model = bmb.Model("p ~ delta_d", df, family="beta")
dirt_fitted = dirt_model.fit()
dirt_model.predict(dirt_fitted, kind="response")Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [kappa, Intercept, delta_d]Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 2 seconds.az.summary(dirt_fitted)| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| kappa | 1848.957 | 82.220 | 1699.006 | 2001.825 | 1.074 | 1.399 | 5869.0 | 3139.0 | 1.0 |
| Intercept | -0.005 | 0.001 | -0.008 | -0.002 | 0.000 | 0.000 | 6484.0 | 2882.0 | 1.0 |
| delta_d | 0.005 | 0.000 | 0.005 | 0.005 | 0.000 | 0.000 | 5909.0 | 3155.0 | 1.0 |
| mu[0] | 0.481 | 0.000 | 0.480 | 0.482 | 0.000 | 0.000 | 6300.0 | 3321.0 | 1.0 |
| mu[1] | 0.529 | 0.001 | 0.528 | 0.530 | 0.000 | 0.000 | 6073.0 | 3261.0 | 1.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| mu[995] | 0.429 | 0.001 | 0.427 | 0.431 | 0.000 | 0.000 | 5966.0 | 3065.0 | 1.0 |
| mu[996] | 0.531 | 0.001 | 0.530 | 0.532 | 0.000 | 0.000 | 6045.0 | 3344.0 | 1.0 |
| mu[997] | 0.478 | 0.000 | 0.477 | 0.478 | 0.000 | 0.000 | 6256.0 | 3191.0 | 1.0 |
| mu[998] | 0.490 | 0.000 | 0.489 | 0.491 | 0.000 | 0.000 | 6416.0 | 3127.0 | 1.0 |
| mu[999] | 0.554 | 0.001 | 0.552 | 0.555 | 0.000 | 0.000 | 5931.0 | 3410.0 | 1.0 |
1003 rows × 9 columns
az.plot_ppc(dirt_fitted);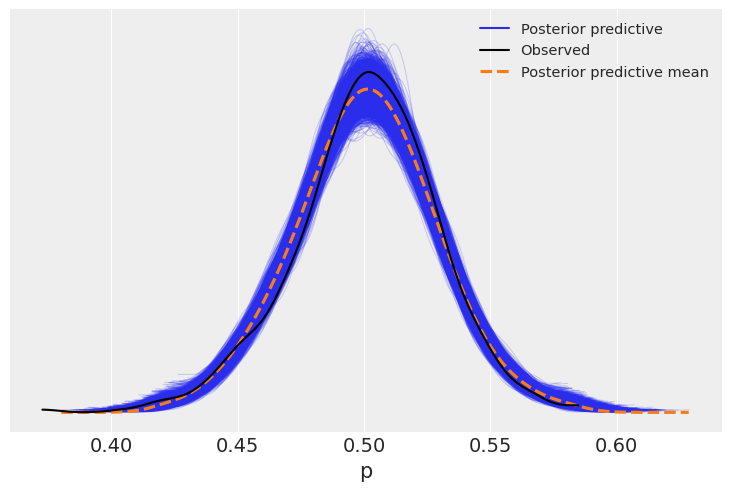
Next, we’ll see if we can in fact recover the effect on \(\alpha\). Remember that in order to return to \(\alpha\), \(\beta\) space, the linear equation passes through an inverse logit transformation, so we must apply this to the coefficient on \(\Delta d\) to get the effect on \(\alpha\). The inverse logit is nicely defined in scipy.special as expit.
mean_effect = expit(dirt_fitted.posterior.delta_d.mean())
hdi = az.hdi(dirt_fitted.posterior.delta_d, hdi_prob=.95)
lower = expit(hdi.delta_d[0])
upper = expit(hdi.delta_d[1])
print(f"Mean effect: {mean_effect.item():.4f}")
print(f"95% interval {lower.item():.4f} - {upper.item():.4f}")Mean effect: 0.5013
95% interval 0.5012 - 0.5013The recovered effect is very close to the true effect of 0.5.
Example - Revisiting Baseball Data
In the Hierarchical Logistic regression with Binomial family notebook, we modeled baseball batting averages (times a player reached first via a hit per times at bat) via a Hierarchical Logisitic regression model. If we’re interested in league-wide effects, we could look at a Beta regression. We work off the assumption that the league-wide batting average follows a Beta distribution, and that individual player’s batting averages are samples from that distribution.
First, load the Batting dataset again, and re-calculate batting average as hits/at-bat. In order to make sure that we have a sufficient sample, we’ll require at least 100 at-bats in order consider a batter. Last, we’ll focus on 1990-2018.
batting = bmb.load_data("batting")batting["batting_avg"] = batting["H"] / batting["AB"]
batting = batting[batting["AB"] > 100]
df = batting[ (batting["yearID"] > 1990) & (batting["yearID"] < 2018) ]df.batting_avg.hist(bins=30)
plt.xlabel("Batting Average")
plt.ylabel("Count");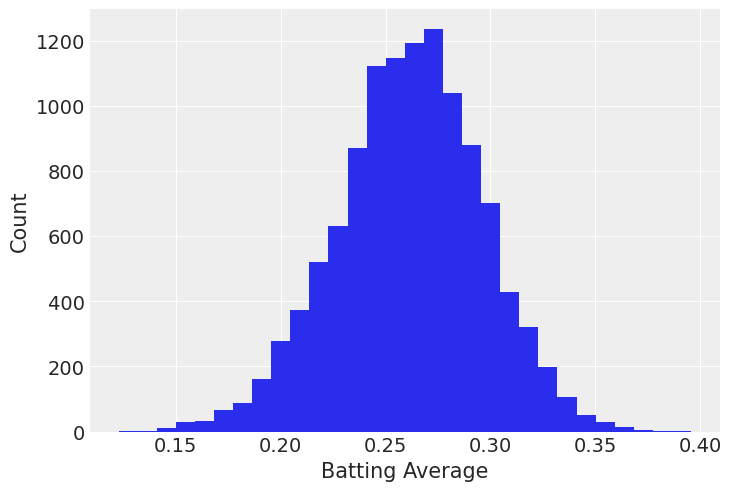
If we’re interested in modeling the distribution of batting averages, we can start with an intercept-only model.
model_avg = bmb.Model("batting_avg ~ 1", df, family="beta")
avg_fitted = model_avg.fit()Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [kappa, Intercept]/Users/hslu-n0006897/projects/bambi/.pixi/envs/dev/lib/python3.13/site-packages/pymc/step_methods/hmc/quadpotential.py:316: RuntimeWarning: overflow encountered in dot
return 0.5 * np.dot(x, v_out)
/Users/hslu-n0006897/projects/bambi/.pixi/envs/dev/lib/python3.13/site-packages/pymc/step_methods/hmc/quadpotential.py:316: RuntimeWarning: overflow encountered in dot
return 0.5 * np.dot(x, v_out)Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 2 seconds.az.summary(avg_fitted)| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| kappa | 152.604 | 1.988 | 148.883 | 156.199 | 0.032 | 0.033 | 3897.0 | 3112.0 | 1.0 |
| Intercept | -1.038 | 0.002 | -1.041 | -1.035 | 0.000 | 0.000 | 3830.0 | 3068.0 | 1.0 |
Looking at the posterior predictive,
posterior_predictive = model_avg.predict(avg_fitted, kind="response")az.plot_ppc(avg_fitted);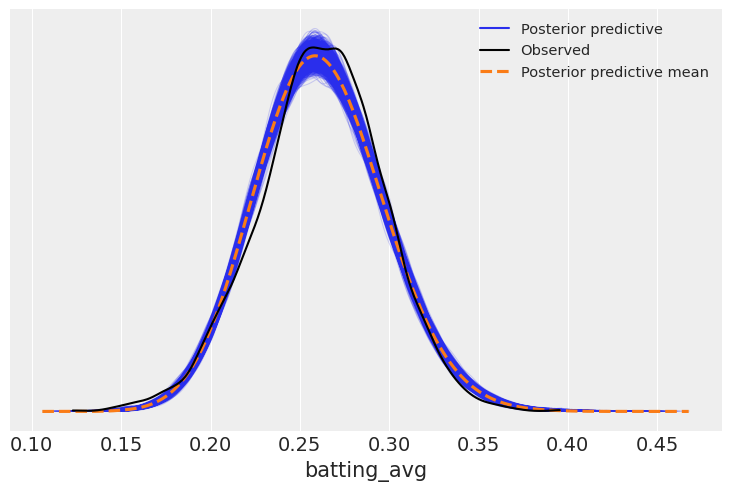
This appears to fit reasonably well. If, for example, we were interested in simulating players, we could sample from this distribution.
However, we can take this further. Say we’re interested in understanding how this distribution shifts if we know a player’s batting average in a previous year. We can condition the model on a player’s n-1 year, and use Beta regrssion to model that. Let’s construct that variable, and for sake of ease, we will ignore players without previous seasons.
# Add the player's batting average in the n-1 year
batting["batting_avg_shift"] = np.where(
batting["playerID"] == batting["playerID"].shift(),
batting["batting_avg"].shift(),
np.nan
)
df_shift = batting[ (batting["yearID"] > 1990) & (batting["yearID"] < 2018) ]
df_shift = df_shift[~df_shift["batting_avg_shift"].isna()]
df_shift[["batting_avg_shift","batting_avg"]].corr()| batting_avg_shift | batting_avg | |
|---|---|---|
| batting_avg_shift | 1.000000 | 0.229774 |
| batting_avg | 0.229774 | 1.000000 |
There is a lot of variance in year-to-year batting averages, it’s not known to be incredibly predictive, and we see that here. A correlation coefficient of 0.23 is only lightly predictive. However, we can still use it in our model to get a better understanding. We’ll fit two models. First, we’ll refit the previous, intercept-only, model using this updated dataset so we have an apples-to-apples comparison. Then, we’ll fit a model using the previous year’s batting average as a predictor.
Notice we need to explicitly ask for the inclusion of the log-likelihood values into the inference data object.
model_avg = bmb.Model("batting_avg ~ 1", df_shift, family="beta")
avg_fitted = model_avg.fit(idata_kwargs={"log_likelihood": True})
model_lag = bmb.Model("batting_avg ~ batting_avg_shift", df_shift, family="beta")
lag_fitted = model_lag.fit(idata_kwargs={"log_likelihood": True})Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [kappa, Intercept]Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 1 seconds.
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [kappa, Intercept, batting_avg_shift]Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 1 seconds.az.summary(lag_fitted)| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| kappa | 135.911 | 9.391 | 118.905 | 153.810 | 0.123 | 0.152 | 5775.0 | 2748.0 | 1.0 |
| Intercept | -1.377 | 0.071 | -1.509 | -1.238 | 0.001 | 0.001 | 6427.0 | 3403.0 | 1.0 |
| batting_avg_shift | 1.356 | 0.272 | 0.853 | 1.878 | 0.003 | 0.004 | 6365.0 | 3267.0 | 1.0 |
az.compare({
"intercept-only" : avg_fitted,
"lag-model": lag_fitted
})| rank | elpd_loo | p_loo | elpd_diff | weight | se | dse | warning | scale | |
|---|---|---|---|---|---|---|---|---|---|
| lag-model | 0 | 784.971866 | 3.065871 | 0.000000 | 0.993512 | 14.547953 | 0.000000 | False | log |
| intercept-only | 1 | 774.178750 | 2.057900 | 10.793116 | 0.006488 | 15.360950 | 4.649934 | False | log |
Adding the predictor results in a higher loo than the intercept-only model.
ppc= model_lag.predict(lag_fitted, kind="response")
az.plot_ppc(lag_fitted);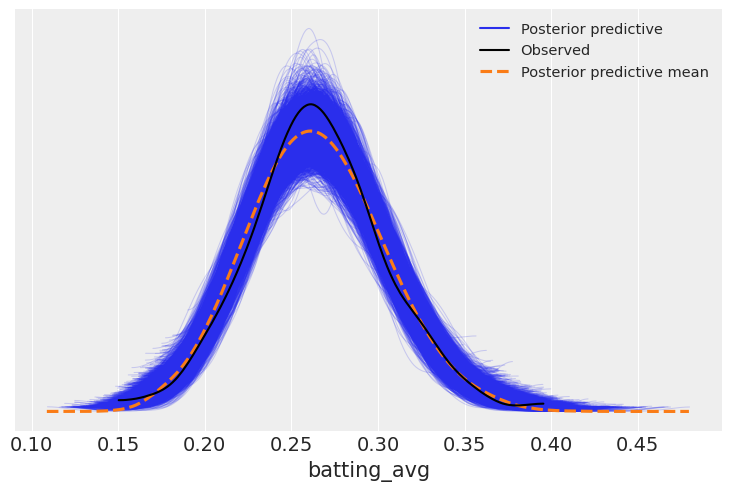
The biggest question this helps us understand is, for each point of batting average in the previous year, how much better do we expect a player to be in the current year?
mean_effect = lag_fitted.posterior.batting_avg_shift.mean().item()
hdi = az.hdi(lag_fitted.posterior.batting_avg_shift, hdi_prob=.95)
lower = expit(hdi.batting_avg_shift[0]).item()
upper = expit(hdi.batting_avg_shift[1]).item()
print(f"Mean effect: {expit(mean_effect):.4f}")
print(f"95% interval {lower:.4f} - {upper:.4f}")Mean effect: 0.7951
95% interval 0.6920 - 0.8683p = bmb.interpret.plot_predictions(
model_lag,
lag_fitted,
conditional="batting_avg_shift",
target="batting_avg",
prob=[0.68, 0.95],
fig_kwargs={"xlabel": "Previous Year's Batting Average", "ylabel": "Batting Average"}
)
p.plot(True).show()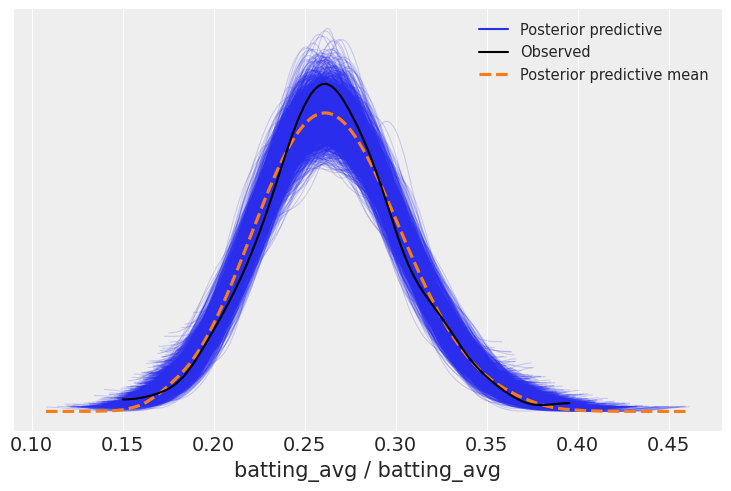
%load_ext watermark
%watermark -n -u -v -iv -wLast updated: Mon, 16 Mar 2026
Python implementation: CPython
Python version : 3.13.12
IPython version : 9.10.0
arviz : 0.23.4
bambi : 0.1.dev891+g05567136c.d20260223
matplotlib: 3.10.8
numpy : 2.3.5
pandas : 2.3.3
scipy : 1.17.0
Watermark: 2.6.0